







...





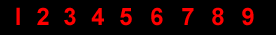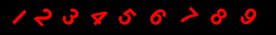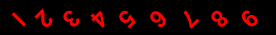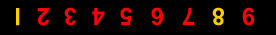
26 |
|
|
|
|
|
|
|
|
I |
|
|
|
|
|
|
|
|
R |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
8 |
9 |
|
|
|
|
5 |
6 |
|
|
|
1 |
|
|
|
|
6 |
|
8 |
+ |
= |
|
4+3 |
= |
|
= |
|
= |
|
|
|
|
|
|
|
|
|
8 |
9 |
|
|
|
|
14 |
15 |
|
|
|
19 |
|
|
|
|
24 |
|
26 |
+ |
= |
|
1+1+5 |
= |
|
= |
|
= |
|
26 |
|
|
|
|
|
|
|
|
I |
|
|
|
|
|
|
|
|
R |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|
|
1 |
2 |
3 |
4 |
|
|
7 |
8 |
9 |
|
2 |
3 |
4 |
5 |
|
7 |
|
+ |
= |
|
8+3 |
= |
|
1+1 |
|
= |
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|
|
10 |
11 |
12 |
13 |
|
|
16 |
17 |
18 |
|
20 |
21 |
22 |
23 |
|
25 |
|
+ |
= |
|
2+3+6 |
= |
|
1+1 |
|
= |
|
26 |
|
|
|
|
|
|
|
|
I |
|
|
|
|
|
|
|
|
R |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
+ |
= |
|
3+5+1 |
= |
|
= |
|
= |
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
+ |
= |
|
1+2+6 |
= |
|
= |
|
= |
|
26 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
R |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
+ |
= |
|
occurs |
x |
3 |
= |
|
|
|
|
|
2 |
|
|
|
|
|
|
|
|
2 |
|
|
|
|
|
|
|
|
2 |
|
|
|
|
|
|
+ |
= |
|
occurs |
x |
3 |
= |
|
|
|
|
|
|
3 |
|
|
|
|
|
|
|
|
3 |
|
|
|
|
|
|
|
|
3 |
|
|
|
|
|
+ |
= |
|
occurs |
x |
3 |
= |
|
|
|
|
|
|
|
4 |
|
|
|
|
|
|
|
|
4 |
|
|
|
|
|
|
|
|
4 |
|
|
|
|
+ |
= |
|
occurs |
x |
3 |
= |
|
1+2 |
|
|
|
|
|
|
5 |
|
|
|
|
|
|
|
|
5 |
|
|
|
|
|
|
|
|
5 |
|
|
|
+ |
= |
|
occurs |
x |
3 |
= |
|
1+5 |
|
|
|
|
|
|
|
6 |
|
|
|
|
|
|
|
|
6 |
|
|
|
|
|
|
|
|
6 |
|
|
+ |
= |
|
occurs |
x |
3 |
= |
|
1+8 |
|
|
|
|
|
|
|
|
7 |
|
|
|
|
|
|
|
|
7 |
|
|
|
|
|
|
|
|
7 |
|
+ |
= |
|
occurs |
x |
3 |
= |
|
2+1 |
|
|
|
|
|
|
|
|
|
8 |
|
|
|
|
|
|
|
|
8 |
|
|
|
|
|
|
|
|
8 |
+ |
= |
|
occurs |
x |
3 |
= |
|
2+4 |
|
|
|
|
|
|
|
|
|
|
9 |
|
|
|
|
|
|
|
|
9 |
- |
- |
- |
- |
- |
- |
- |
- |
+ |
= |
|
occurs |
x |
2 |
= |
|
1+8 |
|
26 |
|
|
|
|
|
|
|
|
I |
|
|
|
|
|
|
|
|
R |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
4+5 |
|
|
2+6 |
|
1+2+6 |
|
5+4 |
26 |
|
|
|
|
|
|
|
|
I |
|
|
|
|
|
|
|
|
R |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
|
|
|
|
|
|
|
|
|
|
26 |
|
|
|
|
|
|
|
|
I |
|
|
|
|
|
|
|
|
R |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
THE LIGHT IS RISING NOW RISING IS THE LIGHT
....
A
MAZE
IN
ZAZAZA ENTERS AZAZAZ
AZAZAZAZAZAZAZZAZAZAZAZAZAZA
ZAZAZAZAZAZAZAZAZAAZAZAZAZAZAZAZAZAZ
THE
MAGICALALPHABET
ABCDEFGHIJKLMNOPQRSTUVWXYZZYXWVUTSRQPONMLKJIHGFEDCBA
12345678910111213141516171819202122232425262625242322212019181716151413121110987654321
18 |
THE ENGLISH ALPHABET |
- |
- |
- |
|
THE |
33 |
15 |
|
|
ENGLISH |
74 |
38 |
|
|
ALPHABET |
65 |
29 |
|
18 |
THE ENGLISH ALPHABET |
172 |
82 |
10 |
| 1+8 |
- |
1+7+2 |
8+2 |
1+0 |
9 |
THE ENGLISH ALPHABET |
10 |
10 |
10 |
- |
- |
1+0 |
1+0 |
1+0 |
9 |
THE ENGLISH ALPHABET |
1 |
1 |
1 |
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
1 2 3 4 5 6 7 8 9 1 2 3 4 5 6 7 8 9 1 2 3 4 5 6 7 8
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
BEYOND THE VEIL ANOTHER VEIL ANOTHER VEIL BEYOND
A
HISTORY OF GOD
Karen Armstrong 1993
The God of the Mystics
Page 250
"Perhaps the most famous of the early Jewish mystical texts is the fifth century Sefer Yezirah (The Book of Creation). There is no attempt to describe the creative process realistically;
the account is unashamedly symbolic and shows God creating the world by means of language as though he were writing a book. But language has been entirely transformed and the message of creation is no longer clear. Each letter of the Hebrew alphabet is given a numerical value; by
combining the letters with the sacred numbers, rearranging them in
endless configurations, the mystic weaned his mind away from the normal connotations of words."
Page 250
THERE IS NO ATTEMPT MADE TO DESCRIBE THE CREATIVE PROCESS REALISTICALLY THE ACCOUNT
IS UNASHAMEDLY SYMBOLIC AND SHOWS GOD CREATING THE WORLD BY MEANS OF LANGUAGE AS
THOUGH HE WERE WRITING A BOOK. BUT LANGUAGE HAS BEEN ENTIRELY TRANSFORMED AND THE
MESSAGE OF CREATION IS NO LONGER CLEAR EACH LETTER OF THE HEBREW ALPHABET IS GIVEN
A NUMERICAL VALUE BY COMBINING THE LETTERS WITH THE SACRED NUMBERS REARRANGING
THEM IN ENDLESS CONFIGURATIONS THE MYSTIC WEANED THE MIND AWAY FROM THE NORMAL
CONNOTATIONS OF WORDS

THE LIGHT IS RISING NOW RISING IS THE LIGHT
....
AMEN THE NAME
WORK DAYS OF GOD
Herbert W Morris D.D.circa 1883
Page 22
"As all the words in the English language are composed out of the twenty-six letters of the alphabet,.."
LIGHT AND LIFE
Lars Olof Bjorn 1976
Page 197
"By writing the 26 letters of the alphabet in a certain order one may put down almost any message (this book 'is written with the same letters' as the Encyclopaedia Britannica and Winnie the Pooh, only the order of the letters differs). In the same way Nature is able to convey with her language how a cell and a whole organism is to be constructed and how it is to function. Nature has succeeded better than we humans; for the genetic code there is only one universal language which is the same in a man, a bean plant and a bacterium."
"BY WRITING THE 26 LETTERS OF THE ALPHABET IN A CERTAIN ORDER
ONE MAY PUT DOWN ALMOST ANY MESSAGE"
A |
B |
C |
D |
E |
F |
G |
H |
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
J |
K |
L |
M |
N |
O |
P |
Q |
R |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
1+0 |
1+1 |
1+2 |
1+3 |
1+4 |
1+5 |
1+6 |
1+7 |
1+8 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
S |
T |
U |
V |
W |
X |
Y |
Z |
I |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
9 |
1+9 |
2+0 |
2+1 |
2+2 |
2+3 |
2+4 |
2+5 |
2+6 |
ME |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
I |
ME |
I |
ME |
I |
ME |
I |
ME |
I |
9 |
18 |
9 |
18 |
9 |
18 |
9 |
18 |
9 |
= |
1+8 |
= |
1+8 |
= |
1+8 |
= |
1+8 |
= |
= |
9 |
= |
9 |
= |
9 |
= |
9 |
= |
I |
ME |
I |
ME |
I |
ME |
I |
ME |
1 |
9 |
9 |
9 |
9 |
9 |
9 |
9 |
9 |
9 |
I |
ME |
I |
ME |
I |
ME |
I |
ME |
1 |
"BY WRITING THE 26 LETTERS OF THE ALPHABET IN A CERTAIN ORDER
ONE MAY PUT DOWN ALMOST ANY MESSAGE"
A |
B |
C |
D |
E |
F |
G |
H |
I |
J |
K |
L |
M |
N |
O |
P |
Q |
R |
S |
T |
U |
V |
W |
X |
Y |
Z |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
|
|
|
|
|
|
|
|
|
1+0 |
1+1 |
1+2 |
1+3 |
1+4 |
1+5 |
1+6 |
1+7 |
1+8 |
1+9 |
2+0 |
2+1 |
2+2 |
2+3 |
2+4 |
2+5 |
2+6 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
A |
B |
C |
D |
E |
F |
G |
H |
|
J |
K |
L |
M |
N |
O |
P |
Q |
R |
S |
T |
U |
V |
W |
X |
Y |
Z |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
A |
B |
C |
D |
E |
F |
G |
H |
I |
J |
K |
L |
M |
N |
O |
P |
Q |
R |
S |
T |
U |
V |
W |
X |
Y |
Z |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
A |
B |
C |
D |
E |
F |
G |
H |
I |
J |
K |
L |
M |
N |
O |
P |
Q |
R |
S |
T |
U |
V |
W |
X |
Y |
Z |
A
HISTORY OF GOD
Karen Armstrong
The God of the Mystics
Page 250
"(The Book of Creation). There is no attempt to describe the creative process realistically; the account is unashamedly symbolic and shows God creating the world by means of language as though he were writing a book. But language has been entirely transformed and the message of creation is no longer clear. Each letter of the Hebrew alphabet is given a numerical value; by combining the letters with the sacred numbers, rearranging them in endless configurations, the mystic weaned his mind away from the normal connotations of words."
A |
B |
C |
D |
E |
F |
G |
H |
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
J |
K |
L |
M |
N |
O |
P |
Q |
R |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
1+0 |
1+1 |
1+2 |
1+3 |
1+4 |
1+5 |
1+6 |
1+7 |
1+8 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
S |
T |
U |
V |
W |
X |
Y |
Z |
I |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
9 |
1+9 |
2+0 |
2+1 |
2+2 |
2+3 |
2+4 |
2+5 |
2+6 |
ME |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
I |
ME |
I |
ME |
I |
ME |
I |
ME |
I |
9 |
18 |
9 |
18 |
9 |
18 |
9 |
18 |
9 |
= |
1+8 |
= |
1+8 |
= |
1+8 |
= |
1+8 |
= |
= |
9 |
= |
9 |
= |
9 |
= |
9 |
= |
I |
ME |
I |
ME |
I |
ME |
I |
ME |
1 |
9 |
9 |
9 |
9 |
9 |
9 |
9 |
9 |
9 |
I |
ME |
I |
ME |
I |
ME |
I |
ME |
1 |
THERE IS NO ATTEMPT MADE TO DESCRIBE THE CREATIVE PROCESS REALISTICALLY
THE ACCOUNT IS SYMBOLIC AND SHOWS GOD CREATING THE WORLD BY MEANS OF LANGUAGE
AS THOUGH WRITING A BOOK BUT LANGUAGE ENTIRELY TRANSFORMED
THE MESSAGE OF CREATION IS CLEAR EACH LETTER OF
THE
ALPHABET
IS
GIVEN
A
NUMERICAL
VALUE BY COMBINING THE LETTERS WITH THE SACRED NUMBERS
REARRANGING THEM IN ENDLESS CONFIGURATIONS
THE MYSTIC WEANED THE MIND AWAY FROM THE NORMAL CONNOTATIONS OF WORDS
A |
B |
C |
D |
E |
F |
G |
H |
I |
J |
K |
L |
M |
N |
O |
P |
Q |
R |
S |
T |
U |
V |
W |
X |
Y |
Z |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
|
|
|
|
|
|
|
|
|
1+0 |
1+1 |
1+2 |
1+3 |
1+4 |
1+5 |
1+6 |
1+7 |
1+8 |
1+9 |
2+0 |
2+1 |
2+2 |
2+3 |
2+4 |
2+5 |
2+6 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
A |
B |
C |
D |
E |
F |
G |
H |
|
J |
K |
L |
M |
N |
O |
P |
Q |
R |
S |
T |
U |
V |
W |
X |
Y |
Z |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
A |
B |
C |
D |
E |
F |
G |
H |
I |
J |
K |
L |
M |
N |
O |
P |
Q |
R |
S |
T |
U |
V |
W |
X |
Y |
Z |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
A |
B |
C |
D |
E |
F |
G |
H |
I |
J |
K |
L |
M |
N |
O |
P |
Q |
R |
S |
T |
U |
V |
W |
X |
Y |
Z |
FINGERPRINTS OF THE GODS
A QUEST FOR THE BEGINNING AND THE END
Graham Hancock 1995
Chapter 32
Speaking to the Unborn
Page 285
"It is understandable that a huge range of myths from all over the ancient world should describe geological catastrophes in graphic detail. Mankind survived the horror of the last Ice Age, and the most plausible source for our enduring traditions of flooding and freezing, massive volcanism and devastating earthquakes is in the tumultuous upheavals unleashed during the great meltdown of 15,000 to 8000 BC. The final retreat of the ice sheets, and the consequent 300-400 foot rise in global sea levels, took place only a few thousand years before the beginning of the historical period. It is therefore not surprising that all our early civilizations should have retained vivid memories of the vast cataclysms that had terrified their forefathers.
Much harder to explain is the peculiar but distinctive way the myths of cataclysm seem to bear the intelligent imprint of a guiding hand.l Indeed the degree of convergence between such ancient stories is frequently remarkable enough to raise the suspicion that they must all have been 'written' by the same 'author'.
Could that author have had anything to do with the wondrous deity, or superhuman, spoken of in so many of the myths we have reviewed, who appears immediately after the world has been shattered by a horrifying geological catastrophe and brings comfort and the gifts of civilization to the shocked and demoralized survivors?
White and bearded, Osiris is the Egyptian manifestation of this / Page 286 /
universal figure, and it may not be an accident that one of the first acts he is remembered for in myth is the abolition of cannibalism among the primitive inhabitants of the Nile Valley.2 Viracocha, in South America, was said to have begun his civilizing mission immediately after a great flood; Quetzalcoatl, the discoverer of maize, brought the benefits of crops, mathematics, astronomy and a refined culture to Mexico after the Fourth Sun had been overwhelmed by a destroying deluge.
Could these strange myths contain a record of encounters between scattered palaeolithic tribes which survived the last Ice Age and an as yet unidentified high civilization which passed through the same epoch?
And could the myths be attempts to communicate?
A message in the bottle of time"
'Of all the other stupendous inventions,' Galileo once remarked,
what sublimity of mind must have been his who conceived how to communicate his most secret thoughts to any other person, though very distant either in time or place, speaking with those who are in the Indies, speaking to those who are not yet born, nor shall be this thousand or ten thousand years? And with no greater difficulty than the various arrangements of two dozen little signs on paper? Let this be the seal of all the admirable inventions of men.3
If the 'precessional message' identified by scholars like Santillana, von Dechend and Jane Sellers is indeed a deliberate attempt at communication by some lost civilization of antiquity, how come it wasn't just written down and left for us to find? Wouldn't that have been easier than encoding it in myths? Perhaps.
Nevertheless, suppose that whatever the message was written on got destroyed or worn away after many thousands of years? Or suppose that the language in which it was inscribed was later forgotten utterly (like the enigmatic Indus Valley script, which has been studied closely for more than half a century but has so far resisted all attempts at decoding)? It must be obvious that in such circumstances a written / Page 287 / legacy to the future would be of no value at all, because nobody would be able to make sense of it.
What one would look for, therefore, would be a universal language, the kind of language that would be comprehensible to any technologically advanced society in any epoch, even a thousand or ten thousand years into the future. Such languages are few and far between, but mathematics is one of them - and the city of Teotihuacan may be the calling-card of a lost civilization written in the eternal language of mathematics.
Geodetic data, related to the exact positioning of fixed geographical points and to the shape and size of the earth, would also remain valid and recognizable for tens of thousands of years, and might be most conveniently expressed by means of cartography (or in the construction of giant geodetic monuments like the Great Pyramid of Egypt, as
we shall see).
Another 'constant' in our solar system is the language of time: the great but regular intervals of time calibrated by the inch-worm creep of precessional motion. Now, or ten thousand years in the future, a message that prints out numbers like 72 or 2160 or 4320 or 25,920 should be instantly intelligible to any civilization that has evolved a modest talent for mathematics and the ability to detect and measure the almost imperceptible reverse wobble that the sun appears to make along the ecliptic against the background of the fixed stars..."
"What one would look for, therefore, would be a universal language, the kind of language that would be comprehensible to any technologically advanced society in any epoch, even a thousand or ten thousand years into the future. Such languages are few and far between, but mathematics is one of them"
"WRITTEN IN THE ETERNAL LANGUAGE OF MATHEMATICS"
A |
B |
C |
D |
E |
F |
G |
H |
I |
J |
K |
L |
M |
N |
O |
P |
Q |
R |
S |
T |
U |
V |
W |
X |
Y |
Z |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
|
|
|
|
|
|
|
|
|
1+0 |
1+1 |
1+2 |
1+3 |
1+4 |
1+5 |
1+6 |
1+7 |
1+8 |
1+9 |
2+0 |
2+1 |
2+2 |
2+3 |
2+4 |
2+5 |
2+6 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
A |
B |
C |
D |
E |
F |
G |
H |
|
J |
K |
L |
M |
N |
O |
P |
Q |
R |
S |
T |
U |
V |
W |
X |
Y |
Z |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
A |
B |
C |
D |
E |
F |
G |
H |
I |
J |
K |
L |
M |
N |
O |
P |
Q |
R |
S |
T |
U |
V |
W |
X |
Y |
Z |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
A |
B |
C |
D |
E |
F |
G |
H |
I |
J |
K |
L |
M |
N |
O |
P |
Q |
R |
S |
T |
U |
V |
W |
X |
Y |
Z |

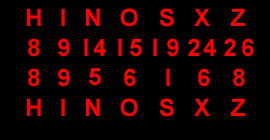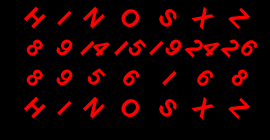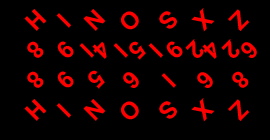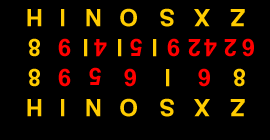
A |
B |
C |
D |
E |
F |
G |
H |
I |
J |
K |
L |
M |
N |
O |
P |
Q |
R |
S |
T |
U |
V |
W |
X |
Y |
Z |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
|
|
|
|
|
|
|
|
|
1+0 |
1+1 |
1+2 |
1+3 |
1+4 |
1+5 |
1+6 |
1+7 |
1+8 |
1+9 |
2+0 |
2+1 |
2+2 |
2+3 |
2+4 |
2+5 |
2+6 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
A |
B |
C |
D |
E |
F |
G |
H |
|
J |
K |
L |
M |
N |
O |
P |
Q |
R |
S |
T |
U |
V |
W |
X |
Y |
Z |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
A |
B |
C |
D |
E |
F |
G |
H |
I |
J |
K |
L |
M |
N |
O |
P |
Q |
R |
S |
T |
U |
V |
W |
X |
Y |
Z |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
A |
B |
C |
D |
E |
F |
G |
H |
I |
J |
K |
L |
M |
N |
O |
P |
Q |
R |
S |
T |
U |
V |
W |
X |
Y |
Z |
A |
B |
C |
D |
E |
F |
G |
H |
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
J |
K |
L |
M |
N |
O |
P |
Q |
R |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
1+0 |
1+1 |
1+2 |
1+3 |
1+4 |
1+5 |
1+6 |
1+7 |
1+8 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
S |
T |
U |
V |
W |
X |
Y |
Z |
I |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
9 |
1+9 |
2+0 |
2+1 |
2+2 |
2+3 |
2+4 |
2+5 |
2+6 |
ME |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
I |
ME |
I |
ME |
I |
ME |
I |
ME |
I |
9 |
18 |
9 |
18 |
9 |
18 |
9 |
18 |
9 |
= |
1+8 |
= |
1+8 |
= |
1+8 |
= |
1+8 |
= |
= |
9 |
= |
9 |
= |
9 |
= |
9 |
= |
I |
ME |
I |
ME |
I |
ME |
I |
ME |
1 |
9 |
9 |
9 |
9 |
9 |
9 |
9 |
9 |
9 |
I |
ME |
I |
ME |
I |
ME |
I |
ME |
1 |
THE
FAR YONDER SCRIBE
AND OFT TIMES SHADOWED SUBSTANCES WATCHED IN SOME AMAZE
THE
ZED ALIZ ZED
IN
SWIFT REPEAT SCATTER STAR DUST AMONGST THE LETTERS OF THEIR PROGRESS

NUMBER
9
THE SEARCH FOR THE SIGMA CODE
Cecil Balmond 1998
Cycles and Patterns
Page 165
Patterns
"The essence of mathematics is to look for patterns.
Our minds seem to be organised to search for relationships and sequences. We look for hidden orders.
These intuitions seem to be more important than the facts themselves, for there is always the thrill at finding something, a pattern, it is a discovery - what was unknown is now revealed. Imagine looking up at the stars and finding the zodiac!
Searching out patterns is a pure delight.
Suddenly the counters fall into place and a connection is found, not necessarily a geometric one, but a relationship between numbers, pictures of the mind, that were not obvious before. There is that excitement of finding order in something that was otherwise hidden.
And there is the knowledge that a huge unseen world lurks behind the facades we see of the numbers themselves."
A |
B |
C |
D |
E |
F |
G |
H |
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
J |
K |
L |
M |
N |
O |
P |
Q |
R |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
1+0 |
1+1 |
1+2 |
1+3 |
1+4 |
1+5 |
1+6 |
1+7 |
1+8 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
S |
T |
U |
V |
W |
X |
Y |
Z |
I |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
9 |
1+9 |
2+0 |
2+1 |
2+2 |
2+3 |
2+4 |
2+5 |
2+6 |
ME |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
= |
I |
ME |
I |
ME |
I |
ME |
I |
ME |
I |
9 |
18 |
9 |
18 |
9 |
18 |
9 |
18 |
9 |
= |
1+8 |
= |
1+8 |
= |
1+8 |
= |
1+8 |
= |
= |
9 |
= |
9 |
= |
9 |
= |
9 |
= |
I |
ME |
I |
ME |
I |
ME |
I |
ME |
1 |
9 |
9 |
9 |
9 |
9 |
9 |
9 |
9 |
9 |
I |
ME |
I |
ME |
I |
ME |
I |
ME |
1 |
- |
|
- |
- |
- |
|
THE |
33 |
15 |
|
|
RAINBOW |
82 |
37 |
|
|
LIGHT |
56 |
29 |
|
15 |
|
171 |
81 |
9 |
1+5 |
|
1+7+1 |
8+1 |
- |
6 |
|
9 |
9 |
9 |
3 |
3 |
- |
A+B+C |
6 |
6 |
6 |
2 |
- |
2 |
D+E |
9 |
9 |
9 |
3 |
3 |
- |
F+G+H |
21 |
21 |
3 |
1 |
- |
1 |
I |
9 |
9 |
9 |
3 |
3 |
|
J+K+L |
33 |
6 |
6 |
2 |
- |
2 |
M+N |
27 |
9 |
9 |
2 |
2 |
|
O+P |
31 |
13 |
4 |
3 |
- |
3 |
QRS |
54 |
18 |
9 |
3 |
- |
3 |
TUV |
63 |
9 |
9 |
3 |
- |
3 |
WXY |
72 |
18 |
9 |
1 |
1 |
- |
Z |
26 |
8 |
8 |
26 |
12 |
14 |
First Total |
351 |
126 |
81 |
2+6 |
1+2 |
1+4 |
Add to Reduce |
3+5+1 |
1+2+6 |
8+1 |
8 |
3 |
5 |
Reduce to Deduce |
9 |
9 |
9 |
3 |
A+B+C |
6 |
6 |
6 |
- |
D+E |
- |
- |
- |
3 |
F+G+H |
21 |
21 |
3 |
- |
I |
- |
- |
- |
3 |
J+K+L |
33 |
6 |
6 |
- |
M+N |
- |
- |
- |
2 |
O+P |
31 |
13 |
4 |
- |
QRS |
- |
- |
- |
- |
TUV |
- |
- |
- |
- |
WXY |
- |
- |
- |
1 |
Z |
26 |
8 |
8 |
12 |
First Total |
117 |
54 |
27 |
2+6 |
Add to Reduce |
1+1+7 |
5+4 |
2+7 |
8 |
Reduce to Deduce |
9 |
9 |
9 |
- |
A+B+C |
- |
- |
- |
2 |
D+E |
9 |
9 |
9 |
- |
F+G+H |
- |
- |
- |
1 |
I |
9 |
9 |
9 |
- |
J+K+L |
- |
- |
- |
2 |
M+N |
27 |
9 |
9 |
- |
O+P |
- |
- |
- |
3 |
QRS |
54 |
18 |
9 |
3 |
TUV |
63 |
9 |
9 |
3 |
WXY |
72 |
18 |
9 |
- |
Z |
- |
- |
- |
14 |
First Total |
234 |
72 |
54 |
1+4 |
Add to Reduce |
2+3+4 |
7+2 |
5+4 |
5 |
Reduce to Deduce |
9 |
9 |
9 |
4 |
ZERO |
64 |
28 |
1 |
|
3
|
ONE |
34
|
16
|
7
|
|
3
|
TWO |
58
|
13
|
4
|
|
5
|
THREE |
56
|
29
|
2
|
|
4
|
FOUR |
60
|
24
|
6
|
|
4
|
FIVE |
42
|
24
|
6
|
|
3
|
SIX |
52
|
16
|
7
|
|
5
|
SEVEN |
65
|
20
|
2
|
|
5
|
EIGHT |
49
|
31
|
4
|
|
4
|
NINE |
42
|
24
|
6
|
40 |
- |
522 |
225 |
45 |
4+0 |
- |
5+2+2 |
2+2+5 |
4+5 |
4 |
- |
9 |
9 |
9 |
9 |
|
|
|
|
|
|
|
|
I |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
8 |
9 |
+ |
= |
|
1+7 |
= |
|
|
|
|
|
|
|
|
|
|
|
8 |
9 |
+ |
= |
|
1+7 |
= |
|
|
|
9 |
|
|
|
|
|
|
|
|
I |
|
|
|
|
|
|
|
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|
|
+ |
= |
|
2+8 |
= |
|
1+0 |
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|
|
+ |
= |
|
2+8 |
= |
|
1+0 |
|
9 |
|
|
|
|
|
|
|
|
I |
|
|
|
|
|
|
|
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
+ |
= |
|
4+5 |
= |
|
|
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
+ |
= |
|
4+5 |
= |
|
|
|
9 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
- |
- |
- |
- |
- |
- |
- |
- |
+ |
= |
|
occurs |
x |
1 |
= |
|
|
- |
2 |
- |
- |
- |
- |
- |
- |
- |
+ |
= |
|
occurs |
x |
1 |
= |
|
|
- |
- |
3 |
- |
- |
- |
- |
- |
- |
+ |
= |
|
occurs |
x |
1 |
= |
|
|
- |
- |
- |
4 |
- |
- |
- |
- |
- |
+ |
= |
|
occurs |
x |
1 |
= |
|
|
- |
- |
- |
- |
5 |
- |
- |
- |
- |
+ |
= |
|
occurs |
x |
1 |
= |
|
|
- |
- |
- |
- |
- |
6 |
- |
- |
- |
+ |
= |
|
occurs |
x |
1 |
= |
|
|
- |
- |
- |
- |
- |
- |
7 |
- |
- |
+ |
= |
|
occurs |
x |
1 |
= |
|
|
- |
- |
- |
- |
- |
- |
- |
8 |
- |
+ |
= |
|
occurs |
x |
1 |
= |
|
|
- |
- |
- |
- |
- |
- |
- |
- |
9 |
+ |
= |
|
occurs |
x |
1 |
= |
|
9 |
|
|
|
|
|
|
|
|
I |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
4+5 |
|
|
- |
|
4+5 |
9 |
|
|
|
|
|
|
|
|
I |
|
|
|
|
|
|
|
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
|
|
|
|
|
|
|
9 |
|
|
|
|
|
|
|
|
I |
|
|
|
|
|
|
|
|
9 |
|
|
|
|
|
|
|
|
R |
|
|
|
|
|
|
|
|
|
|
|
|
|
5 |
6 |
|
|
|
+ |
= |
|
1+1 |
= |
|
|
|
|
|
|
|
|
14 |
15 |
|
|
|
+ |
= |
|
1+7 |
= |
|
|
|
9 |
|
|
|
|
|
|
|
|
R |
|
|
|
|
|
|
|
|
|
1 |
2 |
3 |
4 |
|
|
7 |
8 |
9 |
+ |
= |
|
3+4 |
= |
|
|
|
|
10 |
11 |
12 |
13 |
|
|
16 |
17 |
18 |
+ |
= |
|
9+7 |
= |
|
1+6 |
|
9 |
|
|
|
|
|
|
|
|
R |
|
|
|
|
|
|
|
|
|
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
+ |
= |
|
1+2+6 |
= |
|
|
|
|
1+0 |
1+1 |
1+2 |
1+3 |
1+4 |
1+5 |
1+6 |
1+7 |
1+8 |
|
|
|
|
|
|
|
|
9 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
+ |
= |
|
4+5 |
= |
|
|
|
|
|
|
|
|
|
|
|
|
R |
|
|
|
|
|
|
|
|
|
1 |
- |
- |
- |
- |
- |
- |
- |
- |
+ |
= |
|
occurs |
x |
1 |
= |
|
|
- |
2 |
- |
- |
- |
- |
- |
- |
- |
+ |
= |
|
occurs |
x |
1 |
= |
|
|
- |
- |
3 |
- |
- |
- |
- |
- |
- |
+ |
= |
|
occurs |
x |
1 |
= |
|
|
- |
- |
- |
4 |
- |
- |
- |
- |
- |
+ |
= |
|
occurs |
x |
1 |
= |
|
|
- |
- |
- |
- |
5 |
- |
- |
- |
- |
+ |
= |
|
occurs |
x |
1 |
= |
|
|
- |
- |
- |
- |
- |
6 |
- |
- |
- |
+ |
= |
|
occurs |
x |
1 |
= |
|
|
- |
- |
- |
- |
- |
- |
7 |
- |
- |
+ |
= |
|
occurs |
x |
1 |
= |
|
|
- |
- |
- |
- |
- |
- |
- |
8 |
- |
+ |
= |
|
occurs |
x |
1 |
= |
|
- |
- |
- |
- |
- |
- |
- |
- |
- |
9 |
+ |
= |
|
occurs |
x |
1 |
= |
|
9 |
|
|
|
|
|
|
|
|
R |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
4+5 |
|
|
- |
|
4+5 |
9 |
|
|
|
|
|
|
|
|
R |
|
|
|
|
|
|
|
|
| |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
|
|
|
|
|
|
|
9 |
|
|
|
|
|
|
|
|
R |
|
|
|
|
|
|
|
|
8 |
S |
T |
U |
V |
W |
X |
Y |
Z |
|
|
|
|
|
|
|
|
|
1 |
|
|
|
- |
6 |
|
8 |
+ |
= |
|
1+5 |
= |
|
|
|
|
19 |
|
|
|
- |
24 |
|
26 |
+ |
= |
|
6+9 |
= |
|
|
|
8 |
S |
T |
U |
V |
W |
X |
Y |
Z |
|
|
|
|
|
|
|
|
|
- |
2 |
3 |
4 |
5 |
|
7 |
- |
+ |
= |
|
2+1 |
= |
|
|
|
|
- |
20 |
21 |
22 |
23 |
|
25 |
- |
+ |
= |
|
1+1+1 |
= |
|
- |
|
8 |
S |
T |
U |
V |
W |
X |
Y |
Z |
|
|
|
|
|
|
|
|
|
19 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
+ |
= |
|
1+8+0 |
= |
|
|
|
|
1+9 |
2+0 |
2+1 |
2+2 |
2+3 |
2+4 |
2+5 |
2+6 |
|
|
|
|
|
|
|
|
- |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
+ |
= |
|
3+6 |
= |
|
|
|
8 |
S |
T |
U |
V |
W |
X |
Y |
Z |
|
|
|
|
|
|
|
|
|
1 |
- |
- |
- |
- |
- |
- |
- |
+ |
= |
|
occurs |
x |
1 |
= |
|
|
- |
2 |
- |
- |
- |
- |
- |
- |
+ |
= |
|
occurs |
x |
1 |
= |
|
|
- |
- |
3 |
- |
- |
- |
- |
- |
+ |
= |
|
occurs |
x |
1 |
= |
|
|
- |
- |
- |
4 |
- |
- |
- |
- |
+ |
= |
|
occurs |
x |
1 |
= |
|
|
- |
- |
- |
- |
5 |
- |
- |
- |
+ |
= |
|
occurs |
x |
1 |
= |
|
|
- |
- |
- |
- |
- |
6 |
- |
- |
+ |
= |
|
occurs |
x |
1 |
= |
|
|
- |
- |
- |
- |
- |
- |
7 |
- |
+ |
= |
|
occurs |
x |
1 |
= |
|
|
- |
- |
- |
- |
- |
- |
- |
8 |
+ |
= |
|
occurs |
x |
1 |
= |
|
8 |
S |
T |
U |
V |
W |
X |
Y |
Z |
|
|
|
|
|
|
|
|
- |
|
|
|
|
|
|
|
|
|
|
3+6 |
|
|
- |
|
3+6 |
|
S |
T |
U |
V |
W |
X |
Y |
Z |
|
|
|
|
|
|
|
|
- |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
|
|
|
|
|
|
|
|
8 |
S |
T |
U |
V |
W |
X |
Y |
Z |
|
|
|
|
|
|
|
|
26 |
|
|
|
|
|
|
|
|
I |
|
|
|
|
|
|
|
|
R |
S |
T |
U |
V |
W |
X |
Y |
Z |
|
|
|
|
|
|
|
|
- |
|
|
|
|
|
|
|
|
|
8 |
9 |
|
|
|
|
5 |
6 |
|
|
|
1 |
|
|
|
- |
6 |
|
8 |
+ |
= |
|
4+3 |
= |
|
|
|
- |
|
|
|
|
|
|
|
|
|
8 |
9 |
|
|
|
|
14 |
15 |
|
|
|
19 |
|
|
|
- |
24 |
|
26 |
+ |
= |
|
1+1+5 |
= |
|
|
|
- |
|
26 |
|
|
|
|
|
|
|
|
I |
|
|
|
|
|
|
|
|
R |
S |
T |
U |
V |
W |
X |
Y |
Z |
|
|
|
|
|
|
|
|
- |
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|
|
1 |
2 |
3 |
4 |
|
|
7 |
8 |
9 |
- |
2 |
3 |
4 |
5 |
|
7 |
- |
+ |
= |
|
8+3 |
= |
|
1+1 |
|
- |
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|
|
10 |
11 |
12 |
13 |
|
|
16 |
17 |
18 |
- |
20 |
21 |
22 |
23 |
|
25 |
- |
+ |
= |
|
2+3+6 |
= |
|
1+1 |
|
- |
|
26 |
|
|
|
|
|
|
|
|
I |
|
|
|
|
|
|
|
|
R |
S |
T |
U |
V |
W |
X |
Y |
Z |
|
|
|
|
|
|
|
|
- |
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
+ |
= |
|
3+5+1 |
= |
|
|
|
- |
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
+ |
= |
|
1+2+6 |
= |
|
|
|
- |
|
26 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
R |
S |
T |
U |
V |
W |
X |
Y |
Z |
|
|
|
|
|
|
|
|
- |
|
|
1 |
- |
- |
- |
- |
- |
- |
- |
- |
1 |
- |
- |
- |
- |
- |
- |
- |
- |
1 |
- |
- |
- |
- |
- |
- |
- |
+ |
= |
|
occurs |
x |
3 |
= |
3 |
- |
|
|
- |
2 |
- |
- |
- |
- |
- |
- |
- |
- |
2 |
- |
- |
- |
- |
- |
- |
- |
- |
2 |
- |
- |
- |
- |
- |
- |
+ |
= |
|
occurs |
x |
3 |
= |
6 |
- |
|
|
- |
- |
3 |
- |
- |
- |
- |
- |
- |
- |
- |
3 |
- |
- |
- |
- |
- |
- |
- |
- |
3 |
- |
- |
- |
- |
- |
+ |
= |
|
occurs |
x |
3 |
= |
9 |
- |
|
|
- |
- |
- |
4 |
- |
- |
- |
- |
- |
- |
- |
- |
4 |
- |
- |
- |
- |
- |
- |
- |
- |
4 |
- |
- |
- |
- |
+ |
= |
|
occurs |
x |
3 |
= |
12 |
1+2 |
|
|
- |
- |
- |
- |
5 |
- |
- |
- |
- |
- |
- |
- |
- |
5 |
- |
- |
- |
- |
- |
- |
- |
- |
5 |
- |
- |
- |
+ |
= |
|
occurs |
x |
3 |
= |
15 |
1+5 |
|
|
- |
- |
- |
- |
- |
6 |
- |
- |
- |
- |
- |
- |
- |
- |
6 |
- |
- |
- |
- |
- |
- |
- |
- |
6 |
- |
- |
+ |
= |
|
occurs |
x |
3 |
= |
18 |
1+8 |
|
|
- |
- |
- |
- |
- |
- |
7 |
- |
- |
- |
- |
- |
- |
- |
- |
7 |
- |
- |
- |
- |
- |
- |
- |
- |
7 |
- |
+ |
= |
|
occurs |
x |
3 |
= |
21 |
2+1 |
|
|
- |
- |
- |
- |
- |
- |
- |
8 |
- |
- |
- |
- |
- |
- |
- |
- |
8 |
- |
- |
- |
- |
- |
- |
- |
- |
8 |
+ |
= |
|
occurs |
x |
3 |
= |
24 |
2+4 |
|
|
- |
- |
- |
- |
- |
- |
- |
- |
9 |
- |
- |
- |
- |
- |
- |
- |
- |
9 |
- |
- |
- |
- |
- |
- |
- |
- |
+ |
= |
|
occurs |
x |
2 |
= |
18 |
1+8 |
|
26 |
|
|
|
|
|
|
|
|
I |
|
|
|
|
|
|
|
|
R |
S |
T |
U |
V |
W |
X |
Y |
Z |
|
|
|
|
|
|
|
- |
- |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
4+5 |
|
|
2+6 |
|
- |
- |
5+4 |
26 |
|
|
|
|
|
|
|
|
I |
|
|
|
|
|
|
|
|
R |
S |
T |
U |
V |
W |
X |
Y |
Z |
|
|
|
|
|
|
|
- |
- |
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
|
|
|
|
|
|
|
- |
- |
|
26 |
|
|
|
|
|
|
|
|
I |
|
|
|
|
|
|
|
|
R |
S |
T |
U |
V |
W |
X |
Y |
Z |
|
|
|
|
|
|
|
- |
- |
|
THE USBORNE BOOK OF
FACTS AND LISTS
Lynn Bressler (no date)
Page 82
10 most spoken languages
Chinese 700,000,000 English 400,000,000 Russian 265,000,000 Spanish 240,000,000 Hindustani 230,000,000 Arabic 146,000,000 Portuguese 145,000,000 Bengali 144,000,000 German 119,000,000 Japanese 116,000,000
The first alphabet
The Phoenicians, who once lived where Syria, Jordan and Lebanon are today, had an alphabet of 29 letters as early as 1,700 BC. It was adopted by the Greeks and the Romans. Through the Romans, who went on to conquer most of Europe, it became the alphabet of Western countries.
Sounds strange
One tribe of Mexican Indians hold entire conversations just by whistling. The different pitches provide meaning.
The Rosetta Stone
The Rosetta Stone was found by Napoleon in the sands of Egypt. It dates to about 196 BC.
On it is an inscription in hieroglyphics and a translation in Greek. , Because scholars knew ancient Greek, they could work out what the Egyptian hieroglyphics meant. From this they learned the language of the ancient Egyptians.
Did You KnowMany Chinese cannot understand each other. They have different ways of speaking (called dialects) in different
parts of the country. But today in schools allover China, the children are being taught one dialect (Mandarin), so that one day all Chinese will understand each other.
Translating computers
Computers can be used to help people of different nationalities, who do not know each others' language, talk to each other. By giving a computer a message in one language it will translate it into another specified language.
Worldwide language
English is spoken either as a first or second language in at least 45 countries. This is more than any other language. It is the language of international business and scientific conferences and is used by airtraffic controllers worldwide. In all, about one third of the world speaks it.
Page 83
Earliest writing Chinese writing has been found on pottery, and even on a tortoise shell, going back 6,000 years. Pictures made the basis for their writing, each picture showing an object or idea. Probably the earliest form of writing came from the Middle East, where Iraq and Iran are now. This region was then ruled by the Sumerians.
The most words
English has more words in it than any other language. There are about1 million in all, a third of which are technical terms. Most
people only use about 1 per cent of the words available, that is, about 10,000. William Shakespeare is reputed to have made most use of the English vocabulary.
A scientific word describing a process in the human cell is 207,000 letters long. This makes this single word equal in length to a short novel or about 80 typed sheets of A4 paper.
Many tongues
A Frenchman, named Georges Henri Schmidt, is fluent (meaning he reads and writes well) in 31 different languages.
International language
Esperanto was invented in the 1880s by a Pole, Dr Zamenhof. It was hoped that it would become the international language of Europe. It took words from many European countries and has a very easy grammar that can be learned in an hour or two.
The same language
The languages of India and Europe may originally come from just one source. Many words in different languages sound similar. For example, the word for King in Latin is Rex, in Indian, Raj, in Italian Re, in French Roi and in Spanish Rey. The original language has been named Indo-European. Basque, spoken in the French and Spanish Pyrenees, is an exception. It seems to have a different source which is still unknown.
Number of alphabets
There are 65 alphabets in use in the world today. Here are some of them: Roman
ABCDEFGHUKLMNOPQRS Greek Russian (Cyrillic) Hebrew Chinese (examples omitted)
DAILY MAIL
Monday, October 8, 2007
Harry Bingham
Page 15
"YOU SAY POTATO, I SAY GHOUGHBTEIGHPTEAU !"
"...Yes you CAN spell potato like that. It's one of the amazing quirks which make English the world's dominant language
"ABOUT three years ago I started researching a book, This Little Britain, about the various ways in which
we Brits have a history .
of being the exception.
In areas such as law, government, economics, agriculture and science, we've often been a uniquely British exception to a general European rule.
Ditto, in such things as men's fashion, Victorian sewers, drunken yobbishness, and - not least - in the whole area of language and literature.
Take spellings. George Bernard Shaw famously commented that English spelling would allow you to write the word 'fish' as 'ghoti' - and it would sound the same (in the latter, the sound 'f' would be from 'gh', as in 'rough'; 'i' would be from 'o' in 'women' and 'sh' as in 'ti' from 'nation').
But he couldn't have been trying all that hard, if that was the best example he came up with. How about 'potato' as in
'ghoughbteighpteau'? That's the sound 'p' as in hiccough, 'o' as in
though, 't' as in debt, 'a' as in neighbour, 't' as in ptomaine, 'o' as in bureau. The fact is that with just 26 letters and 48 different sounds to cope with, there were
always going to be problems. :
Throw in other pronunciation
changes and an appetite for
foreign borrowings, and it's no surprise that English has some of
the most dangerously unpredictable spellings in the world.
If our spellings are painful, however, our grammar has its blessedly simple side. French nouns are either masculine or feminine; French verbs vary with every puff
of the syntactical breeze.
But French is a pretty simple language. Italian has 50 different forms for every verb, ancient Greek more than 300, modern Turkish an eye popping two
million. English, by contrast, has
just four verb forms (bark, barks, barking, barked), two noun forms (dog, dogs), and just one adjectival form (snappy), thus making our language about the least inflected in the world.
If that's a curious fact, the reason why is perhaps odder still. Back in Alfred the Great's England, two language communities - English and Danish - intermingled. Each community could make out the basic words of the other language.
FOR example, the word 'horse' is 'hors' in Old English, 'hossit' in Old Norse. But all those tricksy little word endings would have made no sense at all. So they began to vanish.
Under pressure of trade, friendship and intermarriage, our ancient ancestors did away with inflections almost completely. Confusing at the time, no doubt, but a blessing for those who need to learn the language today.
And there are plenty of people learning it, of course. With about one-and a-half billion non-native speakers, English has become the world's own language - one that accounts for two-thirds of internet content, and a still larger proportion of the world's scientific and technical journals.
It's sometimes suggested that English has achieved its leadership because it's thelanguage of Shakespeare, . because of its unique and beautiful literature.
That's nonsense, of course. English dominates because the British Isles exported English speakers and gunboats in the 19th century, and because America exported Hollywood, GIs and hamburgers in the 20th.
If those Mayflower settlers had
chanced to speak Ubykh (a Caucasian language with 81 consonants and 'three vowels) or Rotokas (a Papua New Guinea language with just six consonants and five vowels), the world would most likely be speaking those fine languages today.
Such dominance has its downside, of course. There are now about 6,800 languages left in the world, compared with perhaps twice that number back at the dawn of agriculture. The remaining languages are now dying at the rate of about one a fortnight.
English is big in other ways too. If you wanted to learn all the words in the Oxford English Dictionary, you'd have to deal with about 500,000 of them (ending with zyxt, a splendid last word by any standards and an archaic Kentish term for thou seest).
Having done that, you'd probably be a bit taken aback to learn the equivalent American dictionary, Webster's, offers a further 450,000 words or so, of which only about half are to be found in the OED, suggesting a pooled total word count of about 750,000.
But there are lots of words that never get in to either dictionary. Flora and fauna are mostly out. So are most acronyms, slang and
dialect. Total that lot up and
you'd get to a million or so. Next, you'd need to deal with scientific and technological terms, adding another million or so words.
Otherlanguages-can't keep up. The official dictionary-based word count of German is fewer than 200,000. The French wordcount is fewer than 100,000. The scale of our vocabulary is impossible to explain, except by recognising that English users are
reckless adopters and inventors.
In the cultural realm, however, mere size is hardly likely to impress. In tenus of Nobel Prizes for literature, the United Kingdom trots home in the bronze medal position (beaten by goldmedallist France, and the silvergong-holder, the US.).
If, on the other hand, you were looking at the total amount of literatureproduced by the British Isles then we would come in level
with France, with 13 prizes.
BUT perhaps that's to measure things the wrong way. If you look at Nobel Prizes by language, then English wins by a country mile 26 laureates vs 13 for France).
More to the point, the Nobel Prize Committee is just that: a committee. Wouldn't it be better to let the world's reading public determine which literature it favours? Alas, there are no reliable global sales figures available.
We do, however, have an index of which authors have written the most translated books. British authors romp home in four of the top five places: Agatha Christie in first, then Enid Blyton, Shakespeare and Barbara Cartland in third to fifth. (The one interloper, Frenchman Jules Verne, is in second place.)
Looking more broadly, British authors dominate the top 40, with some 14 authors on the list, compared with 11 for the United States, and 15 for the entire rest of the world put together.
The obvious conclusion: that we Brits have some natural affinity for words and literature, the way that the Germans 'do' music, or the French 'do' visual art.
Such things run both deep and
ancient. The vernacular literature of Alfred the Great's England was the most developed in Europe. It's perhaps not surprising that the same is arguably still true today."
"YOU SAY POTATO, I SAY GHOUGHBTEIGHPTEAU !"
"How about 'potato' as in
'ghoughbteighpteau'?"
|
|
|
|
|
2 |
G+H |
15 |
15 |
6 |
2 |
O+U |
36 |
9 |
9 |
2 |
G+H |
15 |
15 |
6 |
3 |
B+T+E |
27 |
9 |
9 |
1 |
I |
9 |
9 |
9 |
2 |
G+H |
15 |
15 |
6 |
2 |
P+T |
36 |
9 |
9 |
3 |
E+A+U |
27 |
9 |
9 |
|
|
|
|
|
|
|
1+8+0 |
9+0 |
6+3 |
|
|
|
|
|
T |
= |
2 |
- |
3 |
THE |
33 |
15 |
6 |
A |
= |
1 |
- |
6 |
ANUBIS |
66 |
21 |
3 |
- |
- |
3 |
|
9 |
First Total |
|
|
|
- |
- |
- |
- |
- |
Add to Reduce |
9+9 |
3+6 |
- |
- |
- |
3 |
- |
9 |
Second Total |
|
|
|
- |
- |
- |
- |
- |
Reduce to Deduce |
1+8 |
- |
- |
- |
- |
|
- |
|
Essence of Number |
|
|
|
ANUBIS A DOG FOX IS
ANUBIS A NUMBER IS
F |
= |
6 |
- |
3 |
FOX |
45 |
18 |
9 |
O |
= |
6 |
- |
2 |
OF |
21 |
12 |
3 |
F |
= |
6 |
- |
5 |
FOXES |
69 |
24 |
6 |
- |
- |
18 |
|
10 |
Add to Reduce |
|
|
|
- |
- |
1+8 |
-- |
1+0 |
Reduce to Deduce |
1+3+5 |
5+4 |
1+8 |
- |
- |
9 |
|
1 |
Essence of Number |
|
|
|
|
|
- |
- |
- |
1 |
|
6 |
6 |
|
1 |
|
15 |
6 |
|
1 |
|
24 |
6 |
|
|
|
- |
- |
- |
1 |
|
15 |
6 |
|
1 |
|
6 |
6 |
|
|
FOXES |
- |
- |
- |
1 |
|
6 |
6 |
|
1 |
|
15 |
6 |
|
1 |
|
24 |
6 |
|
2 |
|
24 |
6 |
|
F |
= |
6 |
- |
3 |
FOX |
45 |
18 |
9 |
O |
= |
6 |
- |
2 |
OF |
21 |
12 |
3 |
F |
= |
6 |
- |
5 |
FOXES |
69 |
24 |
6 |
S |
- |
18 |
|
10 |
Add to Reduce |
|
|
|
- |
- |
1+8 |
-`` |
1+0 |
Reduce to Deduce |
1+3+5 |
5+4 |
1+8 |
S |
- |
9 |
|
1 |
Essence of Number |
|
|
|
|
|
- |
- |
- |
1 |
|
6 |
6 |
|
1 |
|
15 |
6 |
|
1 |
|
24 |
6 |
|
|
|
- |
- |
- |
1 |
|
15 |
6 |
|
1 |
|
6 |
6 |
|
|
FOXES |
- |
- |
- |
1 |
|
6 |
6 |
|
1 |
|
15 |
6 |
|
1 |
|
24 |
6 |
|
2 |
|
24 |
6 |
|
- |
10 |
|
|
|
|
|
|
|
|
|
|
|
S |
|
|
|
|
|
|
|
- |
- |
|
- |
- |
- |
6 |
6 |
|
6 |
- |
|
- |
6 |
6 |
|
1 |
|
|
|
3+1 |
= |
|
|
|
|
|
- |
- |
- |
15 |
24 |
|
15 |
- |
|
- |
15 |
24 |
|
19 |
|
|
|
1+1+2 |
= |
4 |
= |
|
|
|
- |
10 |
|
|
|
|
|
|
|
|
|
|
|
S |
|
|
|
|
|
|
|
- |
|
|
- |
- |
6 |
- |
|
|
- |
6 |
|
6 |
- |
|
5 |
- |
|
|
|
2+3 |
= |
|
|
|
|
|
- |
- |
6 |
- |
|
|
- |
6 |
|
6 |
- |
|
5 |
- |
|
|
|
2+3 |
= |
|
|
|
|
|
- |
10 |
|
|
|
|
|
|
|
|
|
|
|
S |
|
|
|
|
|
|
|
- |
|
|
- |
- |
6 |
15 |
24 |
|
15 |
6 |
|
6 |
15 |
24 |
5 |
19 |
|
|
|
1+3+5 |
= |
9 |
= |
|
|
|
- |
- |
6 |
6 |
6 |
|
6 |
6 |
|
6 |
6 |
6 |
5 |
1 |
|
|
|
5+4 |
= |
|
|
|
|
|
- |
10 |
|
|
|
|
|
|
|
|
|
|
|
S |
|
|
|
|
|
|
|
- |
- |
|
- |
- |
|
|
|
|
|
|
|
|
|
|
|
1 |
|
|
|
occurs |
x |
|
= |
1 |
= |
|
|
- |
|
|
|
|
|
|
|
|
|
|
|
- |
|
|
|
TWO |
2 |
|
- |
- |
- |
|
|
- |
|
|
|
|
|
|
|
|
|
|
|
- |
|
|
|
|
|
|
- |
- |
- |
|
|
- |
|
|
|
|
|
|
|
|
|
|
|
- |
|
|
|
|
|
|
- |
- |
- |
|
- |
|
|
|
|
|
|
|
|
|
|
|
|
- |
|
|
|
occurs |
x |
|
= |
5 |
= |
|
- |
|
|
|
6 |
|
|
|
|
|
|
6 |
|
- |
|
|
|
occurs |
x |
|
= |
48 |
= |
|
|
- |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
- |
- |
- |
|
8 |
- |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
- |
- |
- |
|
9 |
- |
|
|
- |
|
|
|
|
|
|
- |
|
|
|
|
|
|
|
|
- |
- |
- |
|
33 |
10 |
|
|
|
|
|
|
|
|
|
|
|
S |
|
|
12 |
|
|
|
|
|
|
|
3+3 |
1+0 |
|
|
6 |
|
|
|
|
|
|
6 |
|
|
|
|
1+2 |
- |
- |
1+0 |
- |
5+4 |
- |
- |
6 |
|
|
|
|
|
|
|
|
|
|
|
|
S |
|
|
3 |
|
|
|
|
|
|
|
- |
- |
|
|
6 |
|
|
|
|
|
|
6 |
5 |
1 |
|
|
|
|
|
|
|
- |
- |
|
6 |
1 |
|
|
|
|
|
|
|
|
|
|
|
S |
|
|
3 |
|
|
|
|
|
|
|
10 |
|
|
|
|
|
|
|
|
|
|
|
S |
|
|
|
|
|
|
|
- |
- |
|
- |
- |
6 |
6 |
|
6 |
- |
|
- |
6 |
6 |
|
1 |
|
|
|
3+1 |
= |
|
|
|
|
|
- |
- |
15 |
24 |
|
15 |
- |
|
- |
15 |
24 |
|
19 |
|
|
|
1+1+2 |
= |
4 |
= |
|
|
|
10 |
|
|
|
|
|
|
|
|
|
|
|
S |
|
|
|
|
|
|
|
- |
|
|
- |
6 |
- |
|
|
- |
6 |
|
6 |
- |
|
5 |
- |
|
|
|
2+3 |
= |
|
|
|
|
|
- |
6 |
- |
|
|
- |
6 |
|
6 |
- |
|
5 |
- |
|
|
|
2+3 |
= |
|
|
|
|
|
10 |
|
|
|
|
|
|
|
|
|
|
|
S |
|
|
|
|
|
|
|
- |
|
|
- |
6 |
15 |
24 |
|
15 |
6 |
|
6 |
15 |
24 |
5 |
19 |
|
|
|
1+3+5 |
= |
9 |
= |
|
|
|
- |
6 |
6 |
6 |
|
6 |
6 |
|
6 |
6 |
6 |
5 |
1 |
|
|
|
5+4 |
= |
|
|
|
|
|
10 |
|
|
|
|
|
|
|
|
|
|
|
S |
|
|
|
|
|
|
|
- |
- |
|
- |
|
|
|
|
|
|
|
|
|
|
|
1 |
|
|
|
occurs |
x |
|
= |
1 |
= |
|
|
|
|
|
|
|
|
|
|
|
|
|
- |
|
|
|
occurs |
x |
|
= |
5 |
= |
|
|
|
|
6 |
|
|
|
|
|
|
6 |
|
- |
|
|
|
occurs |
x |
|
= |
48 |
= |
|
10 |
|
|
|
|
|
|
|
|
|
|
|
S |
|
|
12 |
|
|
|
|
|
|
|
1+0 |
|
|
6 |
|
|
|
|
|
|
6 |
|
|
|
|
1+2 |
- |
- |
1+0 |
- |
5+4 |
- |
- |
|
|
|
|
|
|
|
|
|
|
|
|
S |
|
|
3 |
|
|
|
|
|
|
|
- |
|
|
6 |
|
|
|
|
|
|
6 |
5 |
1 |
|
|
|
|
|
|
|
- |
- |
|
1 |
|
|
|
|
|
|
|
|
|
|
|
S |
|
|
3 |
|
|
|
|
|
|
|
1 THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG 1
2 THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG 2
3 THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG 3
4 THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG 4
5 THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG 5
6 THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG 6
7 THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG 7
8 THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG 8
9 THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG 9
10 THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG 10
11 THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG 11
12 THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG 14
13 THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG 4
14 THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG 14
15 THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG 15
16 THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG 16
17 THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG 17
18 THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG 18
19 THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG 19
20 THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG 20
21 THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG 21
22 THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG 22
23 THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG 23
24 THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG 24
25 THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG 25
26 THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG 26
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
- |
T |
= |
2 |
- |
3 |
|
33 |
15 |
6 |
|
|
|
|
|
|
|
|
|
|
2 |
- |
Q |
= |
8 |
- |
5 |
|
61 |
25 |
7 |
|
|
|
|
|
|
|
|
|
|
3 |
- |
B |
= |
2 |
- |
5 |
|
72 |
27 |
9 |
|
|
|
|
|
|
|
|
|
|
4 |
- |
F |
= |
6 |
- |
3 |
|
45 |
18 |
9 |
|
|
|
|
|
|
|
|
|
|
5 |
- |
J |
= |
1 |
- |
5 |
|
79 |
16 |
7 |
|
|
|
|
|
|
|
|
|
|
6 |
- |
O |
= |
6 |
- |
4 |
|
60 |
24 |
6 |
|
|
|
|
|
|
|
|
|
|
7 |
- |
T |
= |
2 |
- |
3 |
|
33 |
15 |
6 |
|
|
|
|
|
|
|
|
|
|
8 |
- |
L |
= |
3 |
- |
4 |
|
64 |
19 |
1 |
|
|
|
|
|
|
|
|
|
|
9 |
- |
D |
= |
4 |
- |
3 |
|
26 |
17 |
8 |
|
|
|
|
|
|
|
|
|
|
45 |
|
- |
- |
34 |
- |
35 |
Add |
|
|
|
|
|
|
|
|
|
|
|
|
|
4+5 |
|
- |
|
3+4 |
|
3+5 |
Reduce |
4+7+3 |
1+7+6 |
5+9 |
|
|
|
|
|
|
1+8 |
1+4 |
|
1+8 |
9 |
- |
- |
|
|
|
|
Deduce |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
- |
|
- |
|
|
Produce |
1+4 |
1+4 |
1+4 |
|
|
|
|
|
|
|
|
|
|
9 |
- |
- |
- |
7 |
- |
8 |
Essence |
|
|
|
|
|
|
|
|
|
|
|
|
|
1 THE QUICK BROWN FOX JUMP1 OVER THE LAZY DOG 1
2 2HE QUICK BROWN FOX JUMPS OVER 2HE LAZY DOG 2
3 THE Q3I3K BROWN FOX J3MPS OVER THE 3AZY DOG 3
4 THE QUICK BROWN FOX JU4PS OVER THE LAZY 4OG 4
5 THE QUICK BRO55 FOX JUMPS OV5R TH5 LAZY DOG 5
6 THE QUICK BR6WN 666 JUMPS 6VER THE LAZY D6OG 6
7 THE QUICK BROWN FOX JUM7S OVER THE LAZ7 DO7 7
8 T8E 8UICK BROWN FOX JUMPS OVER T8E LA8Y DOG 8
9 THE QU9CK B9OWN FOX JUMPS OVE9 THE LAZY DOG 9
10 THE QUICK BROWN FOX JUMP1 OVER THE LAZY DOG 10
11 2HE QUICK BROWN FOX JUMPS OVER 2HE LAZY DOG 11
12 THE Q3I3K BROWN FOX J3MPS OVER THE 3AZY DOG 12
13 THE QUICK BROWN FOX JU4PS OVER THE LAZY 4OG 13
14 THE QUICK BRO55 FOX JUMPS OV5R TH5 LAZY DOG 14
15 THE QUICK BR6WN 666 JUMPS 6VER THE LAZY D6OG 15
16 THE QUICK BROWN FOX JUM7S OVER THE LAZ7 DO7 16
17 T8E 8UICK BROWN FOX JUMPS OVER T8E LA8Y DOG 17
18 THE QU9CK B9OWN FOX JUMPS OVE9 THE LAZY DOG 18
19 THE QUICK BROWN FOX JUMP1 OVER THE LAZY DOG 19
20 2HE QUICK BROWN FOX JUMPS OVER 2HE LAZY DOG 20
21 THE Q3I3K BROWN FOX J3MPS OVER THE 3AZY DOG 21
22 THE QUICK BROWN FOX JU4PS OVER THE LAZY 4OG 22
23 THE QUICK BRO55 FOX JUMPS OV5R TH5 LAZY DOG 23
24 THE QUICK BR6WN 666 JUMPS 6VER THE LAZY D6OG 24
25 THE QUICK BROWN FOX JUM7S OVER THE LAZ7 DO7 25
26 T8E 8UICK BROWN FOX JUMPS OVER T8E LA8Y DOG 26
The quick brown fox jumps over the lazy dog - Wikipedia ...
From Wikipedia, the free encyclopedia
"The quick brown fox jumps over the lazy dog" is an English-language pangram—a phrase that contains all of the letters of the alphabet.
"The quick brown fox jumps over the lazy dog" is an English-language pangram—a phrase that contains all of the letters of the alphabet. It is used to show fonts and to test typewriters and computer keyboards, and in other applications involving all of the letters in the English alphabet. Owing to its brevity and coherence, it has become widely known
History[edit]
The earliest known appearance of the phrase is from The Michigan School Moderator, a journal that provided many teachers with education-related news and suggestions for lessons.[1] In an article titled "Interesting Notes" in the March 14, 1885 issue, the phrase is given as a suggestion for writing practice: "The following sentence makes a good copy for practice, as it contains every letter of the alphabet: 'A quick brown fox jumps over the lazy dog.'"[2] Note that the phrase in this case begins with the word "A" rather than "The". Several other early sources also use this variation.
As the use of typewriters grew in the late 19th century, the phrase began appearing in typing and stenography lesson books as a practice sentence. Early examples of publications which used the phrase include Illustrative Shorthand by Linda Bronson (1888),[3] How to Become Expert in Typewriting: A Complete Instructor Designed Especially for the Remington Typewriter (1890),[4] and Typewriting Instructor and Stenographer's Hand-book (1892). By the turn of the 20th century, the phrase had become widely known. In the January 10, 1903, issue of Pitman's Phonetic Journal, it is referred to as "the well known memorized typing line embracing all the letters of the alphabet".[5] Robert Baden-Powell's book Scouting for Boys (1908) uses the phrase as a practice sentence for signaling.[6]
The first message sent on the Moscow–Washington hotline was the test phrase "THE QUICK BROWN FOX JUMPED OVER THE LAZY DOG'S BACK 1234567890".[7] Later, during testing, the Russian translators sent a message asking their American counterparts "What does it mean when your people say 'The quick brown fox jumped over the lazy dog?'"[8]
During the 20th century, technicians tested typewriters and teleprinters with repeated lines of "THE QUICK BROWN FOX..." sentence.[9]
THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
- |
T |
= |
2 |
- |
3 |
|
33 |
15 |
6 |
|
|
|
|
|
|
|
|
|
|
2 |
- |
Q |
= |
8 |
- |
5 |
|
61 |
25 |
7 |
|
|
|
|
|
|
|
|
|
|
3 |
- |
B |
= |
2 |
- |
5 |
|
72 |
27 |
9 |
|
|
|
|
|
|
|
|
|
|
4 |
- |
F |
= |
6 |
- |
3 |
|
45 |
18 |
9 |
|
|
|
|
|
|
|
|
|
|
5 |
- |
J |
= |
1 |
- |
5 |
|
79 |
16 |
7 |
|
|
|
|
|
|
|
|
|
|
6 |
- |
O |
= |
6 |
- |
4 |
|
60 |
24 |
6 |
|
|
|
|
|
|
|
|
|
|
7 |
- |
T |
= |
2 |
- |
3 |
|
33 |
15 |
6 |
|
|
|
|
|
|
|
|
|
|
8 |
- |
L |
= |
3 |
- |
4 |
|
64 |
19 |
1 |
|
|
|
|
|
|
|
|
|
|
9 |
- |
D |
= |
4 |
- |
3 |
|
26 |
17 |
8 |
|
|
|
|
|
|
|
|
|
|
45 |
|
- |
- |
34 |
- |
35 |
Add |
|
|
|
|
|
|
|
|
|
|
|
|
|
4+5 |
|
- |
|
3+4 |
|
3+5 |
Reduce |
4+7+3 |
1+7+6 |
5+9 |
|
|
|
|
|
|
1+8 |
1+4 |
|
1+8 |
9 |
- |
- |
|
|
|
|
Deduce |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
- |
|
- |
|
|
Produce |
1+4 |
1+4 |
1+4 |
|
|
|
|
|
|
|
|
|
|
9 |
- |
- |
- |
7 |
- |
8 |
Essence |
|
|
|
|
|
|
|
|
|
|
|
|
|
THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
20 |
2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
8 |
8 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
5 |
5 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
17 |
8 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
21 |
3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
9 |
9 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
3 |
3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
11 |
2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
2 |
2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
18 |
9 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
15 |
6 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
23 |
5 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
14 |
5 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
6 |
6 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
15 |
6 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
24 |
6 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
10 |
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
21 |
3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
13 |
4 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
16 |
7 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
19 |
10 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
15 |
6 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
22 |
4 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
5 |
5 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
18 |
9 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
20 |
2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
8 |
8 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
5 |
5 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
12 |
3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
1 |
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
26 |
8 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
25 |
7 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
4 |
4 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
15 |
6 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
7 |
7 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
34 |
- |
35 |
First Total |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3+4 |
|
3+5 |
Add to Reduce |
4+7+3 |
1+7+6 |
5+9 |
|
|
|
1+2 |
1+2 |
2+5 |
3+6 |
2+1 |
3+2 |
2+7 |
|
|
|
|
|
Second Total |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
- |
|
|
Reduce to Deduce |
1+4 |
1+4 |
1+4 |
|
|
|
|
|
|
|
|
|
|
|
|
7 |
- |
8 |
Essence of Number |
|
|
|
|
|
|
|
|
|
|
|
|
|
THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
10 |
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
19 |
10 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
1 |
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
20 |
2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
11 |
2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
2 |
2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
20 |
2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
21 |
3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
3 |
3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
21 |
3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
12 |
3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
13 |
4 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
22 |
4 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
4 |
4 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
5 |
5 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
23 |
5 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
14 |
5 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
5 |
5 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
5 |
5 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
15 |
6 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
6 |
6 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
15 |
6 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
24 |
6 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
15 |
6 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
15 |
6 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
25 |
7 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
7 |
7 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
16 |
7 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
8 |
8 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
17 |
8 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
8 |
8 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
26 |
8 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
9 |
9 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
18 |
9 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
18 |
9 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
34 |
- |
35 |
First Total |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3+4 |
|
3+5 |
Add to Reduce |
4+7+3 |
1+7+6 |
5+9 |
|
|
|
1+2 |
1+2 |
2+5 |
3+6 |
2+1 |
3+2 |
2+7 |
|
|
|
|
|
Second Total |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
- |
|
|
Reduce to Deduce |
1+4 |
1+4 |
1+4 |
|
|
|
|
|
|
|
|
|
|
|
|
7 |
- |
8 |
Essence of Number |
|
|
|
|
|
|
|
|
|
|
|
|
|
THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
PANGRAM = 7 = PANGRAM
- |
- |
- |
- |
- |
PANGRAM |
- |
- |
- |
P |
= |
7 |
- |
1 |
P |
16 |
7 |
7 |
A |
= |
1 |
- |
1 |
A |
1 |
1 |
1 |
N |
= |
5 |
- |
1 |
N |
14 |
5 |
5 |
G |
= |
7 |
- |
1 |
G |
7 |
7 |
7 |
R |
= |
9 |
- |
1 |
R |
18 |
9 |
9 |
A |
= |
1 |
- |
1 |
A |
1 |
1 |
1 |
M |
= |
4 |
- |
1 |
M |
13 |
4 |
4 |
- |
- |
34 |
- |
|
PANGRAM |
|
|
|
- |
- |
3+4 |
- |
- |
- |
7+0 |
3+4 |
3+4 |
- |
- |
7 |
- |
|
PANGRAM |
|
|
|
What sentence contains all the letters of the alphabet?
Everybody knows one or two pangrams (sentences that use every letter of the alphabet). You've probably seen some of these before: The quick brown fox jumps over a lazy dog. Pack my box with five dozen liquor jugs.
Big on the Internet
Sentences That Contain Every Letter of the Alphabet
by Robert Quigley ( ) | Thursday, August 5th 2010 at 4:23 pm
A pangram, or holoalphabetic sentence, is a sentence that contains every letter of the alphabet at least once. The most famous pangram is probably the thirty-five-letter-long “The quick brown fox jumps over the lazy dog,” which has been used to test typing equipment since at least the late 1800s.
Pangrams are an important tool for testing typing equipment and compactly showing off every letter of a typeface; trying to pack every letter into as short a sentence as possible is also a sort of sport among linguists and puzzle-solvers.
Here are a few that are famous or otherwise cool:
● “Sphinx of black quartz, judge my vow”: Used by Adobe InDesign to display font samples. (29 letters)
●”Jackdaws love my big sphinx of quartz”: Similarly, used by Windows XP for some fonts. (31 letters)
●”Pack my box with five dozen liquor jugs”: According to Wikipedia, this one is used on NASA’s Space Shuttle. (32 letters)
●”The quick onyx goblin jumps over the lazy dwarf”: Flavor text from an Unhinged Magic Card. (39 letters)
●”Cwm fjord bank glyphs vext quiz”: Amazingly, this 26-word-long sentence uses every letter only once, though it uses some pretty archaic words; translates to “Carved symbols in a mountain hollow on the bank of an inlet irritated an eccentric person.”
●”How razorback-jumping frogs can level six piqued gymnasts!”: Not going to win any brevity awards at 49 letters long, but old-time Mac users may recognize it.
●”Cozy lummox gives smart squid who asks for job pen”: A 41-letter tester sentence for Mac computers after System 7.
A few others we like: “Amazingly few discotheques provide jukeboxes”; “‘Now fax quiz Jack!’ my brave ghost pled”; “Watch Jeopardy!, Alex Trebek’s fun TV quiz game.”
(via Wikipedia; title image via woot.)
Pangram - Wikipedia, the free encyclopedia
https://en.wikipedia.org/wiki/Pangram
... pangram. An example is the phrase "Cwm fjord bank glyphs vext quiz" (cwm, a loan word from Welsh, means a steep-sided valley, particularly in Wales).
Pangram
From Wikipedia, the free encyclopedia
This article needs additional citations for verification. Please help improve this article by adding citations to reliable sources. Unsourced material may be challenged and removed. (September 2013)
English language pangram in Baskerville font.
A Pangram (Greek: παν γράμμα, pan gramma, "every letter") or holoalphabetic sentence for a given alphabet is a sentence using every letter of the alphabet at least once. Pangrams have been used to display typefaces, test equipment, and develop skills in handwriting, calligraphy, and keyboarding.
The best known English pangram is "The quick brown fox jumps over the lazy dog." It has been used since at least the late 19th century, was utilized by Western Union to test Telex / TWX data communication equipment for accuracy and reliability, and is now used by a number of computer programs (most notably the font viewer built into Microsoft Windows) to display computer fonts.
An example in another language is the German Victor jagt zwölf Boxkämpfer quer über den großen Sylter Deich, containing all letters used in German, including every umlaut (ä, ö, ü) plus the ß. It has been used since before 1800.
Short pangrams in English are more difficult to come up with and tend to use uncommon words, because the English language uses some letters (especially vowels) much more frequently than others. Longer pangrams may afford more opportunity for humor, cleverness, or thoughtfulness.[1] In a sense, the pangram is the opposite of the lipogram, in which the aim is to omit one or more letters. A perfect pangram contains every letter of the alphabet only once and can be considered an anagram of the alphabet; it is the shortest possible pangram. An example is the phrase "Cwm fjord bank glyphs vext quiz" (cwm, a loan word from Welsh, means a steep-sided valley, particularly in Wales).
Contents [hide]
1 Logographic scripts
2 Self-enumerating pangrams
3 Pangrams in literature
4 See also 4.1 Pangram lists
5 References
Logographic scripts[edit]
Logographic scripts, that is, writing systems composed principally of logograms, cannot be used to produce pangrams in the literal sense, since they are radically different from alphabets or other phonetic writing systems. In such scripts, the total number of signs is large and imprecisely defined, so producing a text with every possible sign is impossible. However, various analogies to pangrams are feasible, including traditional pangrams in a romanization. In Japanese, although typical orthography uses kanji (logograms), pangrams are instead required to contain every kana (syllabic character) when written out in kana alone: the Iroha is a classic example.
In addition, it is possible to create pangrams that demonstrate certain aspects of logographic characters.
Chinese: The Thousand Character Classic is a 1000-character poem in which each character is used exactly once, but it does not include all Chinese characters.
The single character 永 (permanence) incorporates every basic stroke used to write Chinese characters exactly once, as described in the Eight Principles of Yong.
Self-enumerating pangrams[edit]
A self-enumerating pangram is a pangrammatic autogram, or a sentence that inventories its own letters, each of which occurs at least once. The first ever example was produced by Rudy Kousbroek, a Dutch journalist and essayist, who publicly challenged Lee Sallows, a British recreational mathematician resident in the Netherlands, to produce an English translation of his Dutch pangram. In the sequel, Sallows built an electronic "pangram machine", that performed a systematic search among millions of candidate solutions. The machine was successful in identifying the following 'magic' translation:[2][3][4]
This pangram contains four As, one B, two Cs, one D, thirty Es, six Fs, five Gs, seven Hs, eleven Is, one J, one K, two Ls, two Ms, eighteen Ns, fifteen Os, two Ps, one Q, five Rs, twenty-seven Ss, eighteen Ts, two Us, seven Vs, eight Ws, two Xs, three Ys, & one Z.
Other approaches have been taken to find self-enumerating pangrams, too. Chris Patuzzo, a British computer scientist was able to reduce the problem of finding a self-enumerating pangram to the Boolean satisfiability problem. He did this by using a bespoke Hardware description language as a stepping stone and then applied the Tseitin transformation to the resulting chip.[5]
Pangrams in literature[edit]
Pangram "The quick brown fox..." and searches of a shorter pangram are the cornerstone of a plot of the novel by Mark Dunn "Ella Minnow Pea".[6] Search successfully comes to the end with finding "Pack my box with five dozen liquor jugs".
The Evolution of Writing, Reading and Printing of the Alphabet
History of the Latin Alphabet
Latin or Roman script is a series of graphic representative signs (script) based on the letters of the classical Latin alphabet, and derived from a form of the Cumaean Greek version of the Greek alphabet, used by the Etruscans.
The Latin script is the most widely used alphabetic writing system in the world. It is the standard script of the English language and is frequently referred to simply as ‘the alphabet’ in both spoken and written English.
It is a true alphabet (As in, it contains separate letters [not diacritic marks] for both consonants and vowels) which originated in the 7th century BC in Italy and has changed continually over the last 2500 years. It also has roots in the Semitic alphabet and its offshoot alphabets, the Phoenician, Greek, and Etruscan.
NOTE: The Semitic alphabet in its earliest form, the Proto-Sinaitic script of Egypt has yet to be fully deciphered. The earliest known alphabetic (or ‘proto-alphabetic’) inscriptions are written in the so-called Proto-Sinaitic (or Proto-Canaanite) script sporadically attested as being in use across the Sinai Peninsula in Egypt and in Canaan (the latter corresponds roughly to present-day Lebanon, Jordan, Syria and Israel, a land also known as Phoenicia) during the Middle and Late Bronze Age. However, the script did not become widely used until the rise of what were dubbed new Semitic kingdoms in the 13th and 12th centuries BC.
The Phoenician alphabet is a direct continuation of the ‘Proto-Canaanite’ script of the Bronze Age collapse period which overall spanned 3000 BC to 1200 BC, but varied in length between Europe, the Near East and South Asia. The Ahiram epitaph, engraved on the sarcophagus of king Ahiram from about 1200 BC, one of five known Byblian royal inscriptions, shows what is essentially the fully developed Phoenician script.
Over time, the phonetic sound values of some letters changed, some letters were lost and others gained, and several writing styles (‘hands’) developed. Two styles, the minuscule and majuscule hands, were ultimately combined into one script with alternate forms for the lower and upper case letters. Due to classicism, modern uppercase letters differ only slightly from their classical counterparts. There are few regional variants.
The Latin alphabet started out as uppercase serifed (with a slight projection finishing off a stroke of a letter) letters known as roman square capitals. Also known as capitalis monumentalis, inscriptional capitals, elegant capitals and capitalis quadrata, this ancient Roman form of writing, became and still is the basis for modern capital letters.
Meanwhile, the lowercase letters evolved through cursive styles (where some characters are written joined together in a flowing manner, generally for the purpose of making writing faster i.e. what the English refer to as longhand). These styles were fundamentally developed in order to adapt the formerly inscribed alphabet to be written with a pen.
Down through the ages, many dissimilar stylistic variants of each letter have appeared but remain identified as the same original letter. Following the evolution of the *dab* alphabet from the Western Greek Alphabet through Old Italic alphabet, G developed from C, the letter J developed from a flourished I, V and U split and the ligature of VV became W, the letter thorn was introduced from the runic alphabet but was lost in all languages except Icelandic, and the letter s could be written either as a long s (ſ) inside a word or as a terminal s at the end or after a long s (ß) after the 7th century AD, but the long s was generally abandoned in the 19th century.
However, courtesy of classical revival, Roman capitals were reintroduced by humanists making Latin inscriptions easily legible to modern readers while many medieval manuscripts are unreadable to an untrained modern reader, due to unfamiliar letterforms, narrow spacing and abbreviation marks with some exceptions of some marks such as the apostrophe and the exception of Carolingian minuscule letters (lower caps) which were mistaken for Roman.
Additionally the phonetic value of the letters has changed from the original and is certainly not constant across the languages adopting the Latin alphabet, for instance comparing English with French. Quite often the orthography fails to fully match the phonetics, resulting in Homophonic heterographs (words written differently but sounding the same) for example in English rough and ruff and also adopting digraphs covering new sounds, such as ‘sh’ for Voiceless post-alveolar fricative in English.
Development of Letter case within the Latin Alphabet
Letter case (often simply referred to as case) is the distinction between the letters of the alphabet that are written in their larger form known as upper case (however other terms frequently used are uppercase, capital letters, capitals, caps, large letters, or more formally majuscule). In logical contrast the smaller version of letters are known as lower case (other terms regularly in use include lowercase, small letters, along with the more formal minuscule). Both only apply in the written representation of certain languages.
The writing systems that physically distinguish between the upper and lower case employ two parallel sets of letters, where each letter in one set normally has an equivalent in the other set. Fundamentally, the two case variants are alternative presentations of the same letter; they are both assigned the same name as well as pronunciation and have identical values when information is to be sorted in alphabetical order.
The terms upper case and lower case maybe be written as two consecutive words, connected with a hyphen (upper-case and lower-case), or the two components merged as a single word (uppercase and lowercase). In fact, these terms originated from what were the common layouts of the shallow drawers called type cases used to hold the movable type for letterpress printing. Traditionally, the capital letters were stored in a separate shallow tray or ‘case’ that was located above the case which held the small letters, and since capital letters are taller the name proved easy to remember.
Majuscule, is technically any script in which the letters are depicted with very few or short ascenders and descenders, or none at all (for example, the majuscule scripts used in the Codex Vaticanus Graecus 1209, or the Book of Kells). By virtue of their visual impact, this then made the term majuscule an apt descriptor for what much later came to be more commonly referred to as uppercase or capital letters.
The Codex Vaticanus, author Eusebius was completed between 300 and 325 is considered to be one of the oldest extant manuscripts of the Greek Bible (Old and New Testament), and one of the four great uncial codices. The Codex is named after its place of conservation in the Vatican Library, where it has been kept since at least the 15th century.
The Book of Kells (Latin: Codex Cenannensis; Irish: Leabhar Cheanannais is held in Dublin, Trinity College Library in Ireland. Sometimes known as the Book of Columba, it is an illuminated manuscript Gospel book in Latin, containing the four Gospels of the New Testament together with various prefatory texts and tables.
Minuscule refers to lower-case letters. The word is often spelled miniscule, because of its association with the unrelated word miniature and the prefix mini-. Traditionally this has been regarded as a spelling mistake (since minuscule is derived from the word minus), however it is now so common that some dictionaries tend to accept it as a nonstandard or variant spelling. Nevertheless, Miniscule is still less likely to be used in reference to lower-case letters.
Originally alphabets were written entirely in majuscule or capital letters, spaced between well-defined upper and lower bounds. When written quickly with a pen, these tended to result in rounder and much simpler forms. It is from these that the first minuscule writing hands developed, the half-uncials and cursive minuscule, which no longer stayed bound between a pair of lines. These in turn formed the foundations for the Carolingian minuscule script, developed by famous scholar Alcuin of York for use in the court of Charlemagne (742 to 814 AD), which quickly spread across Europe. The advantage of the minuscule over majuscule was supposedly improved, faster readability.
In Latin, papyri from Herculaneum dating before 79 AD (when the ancient Roman town was destroyed by the eruption of Mount Vesuvius) have been found written in old Roman cursive, where the early forms of minuscule letters d’, ‘h’ and ‘r’ for example, can already be recognised. According to papyrologist Knut Kleve, ‘The theory, then, that the lower-case letters have been developed from the fifth century uncials and the ninth century Carolingian minuscules seems to be wrong’. Both majuscule and minuscule letters existed, but the difference between the two variants was initially stylistic rather than orthographic and the writing system was still basically unicameral (of a single legislative body): a given handwritten document could make use of either one style or the other but these were not mixed. European languages did not make the distinction between cases, other than Ancient Greek and Latin until around 1300.
The timeline for writing in Western Europe is divisible into four eras:
Greek majuscule (9th to 3rd century BC) in contrast to the Greek uncial script (3rd century BC to 12th century AD) and the later Greek minuscule
Roman majuscule (7th century BC to 4th century AD) in contrast to the Roman uncial (4th to 8th century AD), Roman Half Uncial, and minuscule
Carolingian majuscule (4th to 8th century AD) in contrast to the Carolingian minuscule (around 780 to 12th century). [Carolingian Empire Franks & Lombards].
Gothic majuscule (13th and 14th century), in contrast to the early Gothic (end of 11th to 13th century), Gothic (14th century), and late Gothic (16th century) minuscules.
NOTE: Uncial is defined as ‘of or written in a majuscule script with rounded unjoined letters which is found in European manuscripts between the 4th and 8th centuries; from which modern capital letters are derived’.
Traditionally, certain letters were rendered differently according to a set of rules. Specifically, those letters that began sentences or nouns were enlarged and often written in a distinct script. There was actually no fixed capitalisation system until the early 18th century. The English language eventually dropped the rule for nouns, while the German language retained it.
Similar evolution has taken place in other alphabets. The lower-case script for the Greek alphabet has its origins in the 7th century and only acquired its quadrilinear form in the 8th century. Over time, uncial letter forms were increasingly mixed into the script. The earliest dated Greek lower-case text is found in the Uspenski Gospels (MS 461 a New Testament minuscule manuscript written in Greek) in the year 835. The modern practice of capitalising the first letter of every sentence appears to have been imported (even today the system is rarely used when printing Ancient Greek materials).
The Evolution of Word Spacing and Punctuation
Modern English, both hand written and printed, uses a space to separate individual words, however not all languages adhere to this practice. In chronological terms spaces were not used to separate words in Latin until roughly 600 to 800 AD, whereas Ancient Hebrew and Arabic did use physical spaces, but partly to compensate for clarity issues arising from the lack of vowels. Traditionally, all CJK languages have had no spaces, and certainly in the main both modern Chinese and Japanese do not; yet conversely modern Korean does use spaces.
Meanwhile, Runic texts make use of either interpunct-like (consisting of a vertically centred dot) or colon-style punctuation marks as word separation devices.
Taking spacing a stage further, essentially it is only those languages based upon a Latin-derived alphabet (English being one) which have adopted a varied methodology of sentence spacing since the advent of movable printing type in the 15th century.
Spacing toward Punctuation
What are known as the Semitic languages (Hebrew, Aramaic, Arabic, and Syriac), especially when written without vowels, were pretty much always recorded with word separation, even in their most ancient form, and indeed continued to be transcribed with this formatting into modern times
The earliest alphabetic based writing had no capitalisation, spaces or vowels and few punctuation marks. However, this system only worked effectively if the subject matter was confined to a limited spread of everyday topics (e.g. written records pertaining to business transactions). Although in real historical terms, punctuation was designed as an aid to reading aloud.
The oldest known document using punctuation is the Mesha Stele (a 9th century BC inscribed stone, set up around 840 BC by King Mesha of Moab Mesha). Mesha Stele is inscribed with the cautionary tale of how Chemosh, the god of Moab, had been angry with his people and as a result allowed them to be subjugated by Israel, but eventually Chemosh returns and helps the people to restore Moab’s independence and throw off the yoke of Israeli oppression. It is written in the Phoenician alphabet and employs points between the words along with horizontal strokes between the sense sections, as punctuation.
The Arrival of Symbolic Punctuation
Most texts of the time were still written in scriptura continua, meaning without any separation between words. However, the Greeks began to sporadically use punctuation marks, consisting of vertically arranged dots [usually two (dicolon) or three (tricolon)], in and around the 5th century b.c. as an aid to the oral delivery of texts. Greek playwrights such as Euripides and Aristophanes definitely used symbols to distinguish the ends of phrases in written drama: essentially helping the thespians to know when to pause. Post 200 b.c., the Greeks used the Aristophanes of Byzantium system (named théseis) of a single dot (punctus) placed at varying heights to mark up speeches at rhetorical dividing lines:
· hypostigmḗ – a low punctus on the baseline to mark off a komma (unit smaller than a clause [a unit of grammatical organisation next below the sentence in rank and in traditional grammar said to consist of a subject and predicate.]);
· stigmḕ mésē – a punctus at midheight to mark off a clause (kōlon); and
· stigmḕ teleía – a high punctus to mark off a sentence (periodos).
In addition, the Greeks used the paragraphos (or gamma) to mark the beginning of sentences, marginal diples (marks once used in margins to draw attention to something in the text.) to mark quotations, and a koronis (both a textual symbol and a mark over vowel letters in Ancient Greek) to indicate the end of major sections.
Circa 1st century b.c., the Romans also occasionally used symbols to indicate pauses, but the Greek théseis, subsequently known by the name distinctiones, prevailed to become a more or less widespread standard from the 1st to the 4th century A.D. Certainly, according to scholarly observer practitioners ranging from Aelius Donatus (Roman grammarian and teacher of rhetoric 1st Century AD) through to Isidore of Seville (Scholar and Archbishop of Seville 7th century AD).
Also, during the 1st century BC, texts were sometimes laid out per capitula, where every sentence had its own separate line. Originally diples were used for these demarcations; however by the late period (664 BC until 332 BC) they had often regressed into comma-shaped marks.
The Development of Punctuation
Punctuation evolved dramatically as copies of the Bible began to be produced in large numbers. Given that it was essential that the holy tome be read aloud, so the copyists began to introduce a range of spoken word marks to help the reader. These included indentation, various punctuation marks (diple, paragraphos, simplex ductus), and an early version of initial capitals (litterae notabiliores).
Jerome (tutored by the aforementioned Aelius Donatus) who along with colleagues, made a translation of the Bible into Latin, the Vulgate around 400 AD, employed a formatting system based on the established methodology used for teaching the speeches of Demosthenes and Cicero. Under this layout per cola et commata every sense-unit was indented and given its own line. However, this layout was solely used for biblical manuscripts in a period covering the 5th to 9th centuries and was then abandoned in favour of punctuation.
Meanwhile in the 7th and 8th centuries Irish and Anglo-Saxon scribes, whose native languages were not derived from Latin, added further visual cues to render texts more intelligible. Irish scribes introduced the practice of word separation. Likewise, insular scribes (post-Roman Hiberno/Saxon) adopted the distinctiones system while adapting it for minuscule script (to make the signage more prominent) not by employing differing height but rather a variable number of marks mainly aligned horizontally (or sometimes triangularly) to indicate a pause's value: one mark for a minor pause, two for the medium version, and three for a major. Most common were the punctus, a comma-shaped mark, and a 7-shaped mark (comma positura), often used in combination. The same symbols could be used in the margin to mark off quotations.
Nevertheless, despite these advances, an alternative system emerged in France during the late 8th century under the Carolingian dynasty. In its original form, this system was used to indicate how the voice should be modulated when chanting the liturgy, but gradually the positurae as it was known, steadily migrated into any text meant to be read aloud, and ultimately to all manuscripts.
Positurae first worked itself into England over the latter part of the 10th century AD, most likely during the Benedictine reform movement, but was not adopted as standard practice until after the Norman Conquest. The original positurae were the punctus, punctus elevatus (an inverted latter day semi-colon), punctus versus, and punctus interrogatives (dot with a flourish above as in the modern day question mark), but a fifth symbol, the punctus flexus (very similar to the punctus interrogatives), was added in the 10th century to indicate a pause of a value between the punctus and punctus elevatus. In the late 11th/early 12th century the punctus versus (similar in appearance to a semicolon) faded away and was taken over by the simple punctus (now with two distinct values).
The arrival of the late Middle Ages saw the addition of the virgula suspensiva (slash or slash with a midpoint dot) which was often used in conjunction with the punctus for different types of pauses. Direct quotations continued to be marked with marginal diples, as they were in antiquity, but from at least the 12th century scribes also began entering diples (sometimes doubled up) within the physical column of text.
Later Developments Leading to Modern Punctutation
The volume of printed material becoming available and thus its readership began to increase after the invention of moveable type in Europe in the 1450s. To quote writer and editor, Lynne Truss, ‘The rise of printing in the 14th and 15th centuries meant that a standard system of punctuation was urgently required.’
The introduction of a standard system of punctuation has also been attributed to the Venetian printers Aldus Manutius (Venetian humanist, scholar, educator, who became a printer and publisher when he helped found the Aldine Press in Venice, 1495) and his grandson. They have been credited with popularising the practice of ending sentences with the colon or full stop, inventing the semicolon (although the punctus versus was still visible in the early 12th century), making occasional use of parentheses and creating the modern comma by lowering the virgule. By 1566, Aldus Manutius the Younger was able to declare that the main objective of punctuation was the clarification of syntax.
In a 19th-century manual of typography, published by American Printer Thomas MacKellar in 1866, he writes:
‘Shortly after the invention of printing, the necessity of stops or pauses in sentences for the guidance of the reader produced the colon and full point. In process of time, the comma was added, which was then merely a perpendicular line, proportioned to the body of the letter. These three points were the only ones used until the close of the fifteenth century, when Aldo Manuccio gave a better shape to the comma, and added the semicolon; the comma denoting the shortest pause, the semicolon next, then the colon, and the full point terminating the sentence. The marks of interrogation and admiration were introduced many years after.’
By the 19th century, punctuation in the western world had evolved ‘to classify the marks hierarchically, in terms of weight’.
Conveying the use of Punctuation by Example
Cecil B. Hartley's teaching poem taken from his title
The Gentlemen's Book of Etiquette and Manual of Politeness,
published in 1860 identifies the relative values of punctuation marks:
The stop point out, with truth, the time of pause
A sentence doth require at ev'ry clause.
At ev'ry comma, stop while one you count;
At semicolon, two is the amount;
A colon doth require the time of three;
The period four, as learned men agree.
The use of punctuation was not standardised until after the invention of printing.According to the 1885 edition of The American Printer, the importance of punctuation was noted in various sayings by children such as:
Charles the First walked and talked
Half an hour after his head was cut off.
With a semi-colon and a comma added it reads:
Charles the First walked and talked;
Half an hour after, his head was cut off.
Andrew M McTiernan 8/November/2017
BBC - Languages - Languages - Languages of the world ...
www.bbc.co.uk/languages/guide/languages.shtml?
Languages of the world. A guide to which languages are most widely spoken, hardest to learn and other revealing facts. Open/close. 1. How many languages ...
It’s estimated that up to 7,000 different languages are spoken around the world. 90% of these languages are used by less than 100,000 people. Over a million people converse in 150-200 languages and 46 languages have just a single speaker!
Languages are grouped into families that share a common ancestry. For example, English is related to German and Dutch, and they are all part of the Indo-European family of languages. These also include Romance languages, such as French, Spanish and Italian, which come from Latin.
2,200 of the world’s languages can be found in Asia, while Europe has a mere 260.
Nearly every language uses a similar grammatical structure, even though they may not be linked in vocabulary or origin. Communities which are usually isolated from each other because of mountainous geography may have developed multiple languages. Papua New Guinea for instance, boasts no less than 832 different languages!
Exactly How Many Languages Are There in the World?
www.translationblog.co.uk/exactly-how-many-languages-are-there-in-th...?
Jan 11, 2010 – One of the challenges we face as a language solutions provider is covering demand for the languages that our clients request on a daily basis.
Richard Loyer | January 11, 2010
Exactly How Many Languages Are There in the World?
One of the challenges we face as a language solutions provider is covering demand for the languages that our clients request on a daily basis. So how many languages are there in the World and how do we go about providing translation and interpreting in all of them….?
The invaluable Ethnologue quotes 6909 living languages, that’s one language for every 862,000 people on Earth. Let’s look at some more figures from Ethnologue’s database.
Europe, with ¼ of the World’s population has only 234 languages spoken on a daily basis.
Although English does well as the World’s business language-at least for the time being- it is only 3rd in the league table of native speakers of a first language, with 328M, only 1m behind Spanish but a long way from the 845M Mandarin speakers.
94% of languages are spoken by only 6% of the World’s population, which tells us that there are hundreds of languages with just a few thousand [or hundred] speakers.
Many of these languages would be classified by some as dialects i.e. languages that have evolved from but are still quite closely related to another. This definition, of course, falls down very rapidly as most Western European languages can trace their roots to Latin but would not normally be described as dialects. Some of the African and Caribbean Patois are still seen as dialects, as was Ulster-Scots until fairly recently when it was recognised as a language. http://www.ulsterscotsagency.com/
The most famous phrase “a language is a dialect with an army and a navy” is wrongly attributed to Yiddish scholar Max Weinreich, who was probably quoting an anonymous teacher from New York, but it is a neat way to make the definition.
So how many of these languages are regularly translated by Applied Language? Well, it’s a lot but not quite 6909…….we reckon that about 200 languages are translated regularly by our global offices into documents, websites, brochures and anything else you can imagine. The range of languages required by our interpreting team is rather smaller at about 100.
The difference is no mystery; companies that translate their promotional material may be selling into every part of the globe and therefore their need is very broad whilst a hospital in Manchester, for example, will only have to deal with the resident non-native speakers and unwell tourists that come through its doors. Although the interpreting requirement is significant, it rarely exceeds 100 different languages.
Some of the most difficult requests are for languages that unfortunately don’t exist; enquiries for “Indian” or “Eastern European” do pop up occasionally. Similarly, “African” or “South American” can have us scratching our heads.
As a final thought for those of you currently learning another language you might be slightly discouraged by a report from Swarthmore College linguist K. David Harrison who predicts that 90% of the World’s languages will be extinct by 2050. http://www.msnbc.msn.com/id/438742
This might make finding translators a little easier, but would surely make our World a rather less interesting place?
Alphabet - Wikipedia, the free encyclopedia
en.wikipedia.org/wiki/Alphabet?
An alphabet is a standard set of letters (basic written symbols or graphemes) which is used to write one or more languages based on the general principle that ...
Alphabet
From Wikipedia, the free encyclopedia
This article is about sets of letters used in written languages. For other uses, see Alphabet (disambiguation).
An alphabet is a standard set of letters (basic written symbols or graphemes) which is used to write one or more languages based on the general principle that the letters represent phonemes (basic significant sounds) of the spoken language. This is in contrast to other types of writing systems, such as syllabaries (in which each character represents a syllable) and logographies (in which each character represents a word, morpheme or semantic unit).
A true alphabet has letters for the vowels of a language as well as the consonants. The first "true alphabet" in this sense is believed to be the Greek alphabet,[1][2] which is a modified form of the Phoenician alphabet. In other types of alphabet either the vowels are not indicated at all, as was the case in the Phoenician alphabet (such systems are known as abjads), or else the vowels are shown by diacritics or modification of consonants, as in the devanagari used in India and Nepal (these systems are known as abugidas or alphasyllabaries).
There are dozens of alphabets in use today, the most popular being the Latin alphabet[3] (which was derived from the Greek). Many languages use modified forms of the Latin alphabet, with additional letters formed using diacritical marks. While most alphabets have letters composed of lines (linear writing), there are also exceptions such as the alphabets used in Braille, fingerspelling, and Morse code.
Alphabets are usually associated with a standard ordering of their letters. This makes them useful for purposes of collation, specifically by allowing words to be sorted in alphabetical order. It also means that their letters can be used as an alternative method of "numbering" ordered items, in such contexts as numbered lists.
Contents
[hide] 1 Etymology
2 History 2.1 Middle Eastern scripts
2.2 European alphabets
2.3 Asian alphabets
3 Types
4 Alphabetical order
5 Names of letters
6 Orthography and pronunciation
7 See also
8 References
9 Bibliography
10 External links
Etymology[edit]
The English word alphabet came into Middle English from the Late Latin word alphabetum, which in turn originated in the Greek ??f?ß?t?? (alphabetos), from alpha and beta, the first two letters of the Greek alphabet.[4] Alpha and beta in turn came from the first two letters of the Phoenician alphabet, and originally meant ox and house respectively.
History[edit]
Main article: History of the alphabet
A Specimen of typeset fonts and languages, by William Caslon, letter founder; from the 1728 Cyclopaedia.
Middle Eastern scripts[edit]
The history of the alphabet started in ancient Egypt. By the 27th century BC Egyptian writing had a set of some 24 hieroglyphs which are called uniliterals,[5] to represent syllables that begin with a single consonant of their language, plus a vowel (or no vowel) to be supplied by the native speaker. These glyphs were used as pronunciation guides for logograms, to write grammatical inflections, and, later, to transcribe loan words and foreign names.[6]
A specimen of Proto-Sinaitic script, one of the earliest (if not the very first) phonemic scripts
In the Middle Bronze Age an apparently "alphabetic" system known as the Proto-Sinaitic script appears in Egyptian turquoise mines in the Sinai peninsula dated to circa the 15th century BC, apparently left by Canaanite workers. In 1999, John and Deborah Darnell discovered an even earlier version of this first alphabet at Wadi el-Hol dated to circa 1800 BC and showing evidence of having been adapted from specific forms of Egyptian hieroglyphs that could be dated to circa 2000 BC, strongly suggesting that the first alphabet had been developed circa that time.[7] Based on letter appearances and names, it is believed to be based on Egyptian hieroglyphs.[8] This script had no characters representing vowels. An alphabetic cuneiform script with 30 signs including three which indicate the following vowel was invented in Ugarit before the 15th century BC. This script was not used after the destruction of Ugarit.[9]
The Proto-Sinaitic script eventually developed into the Phoenician alphabet, which is conventionally called "Proto-Canaanite" before ca. 1050 BC.[10] The oldest text in Phoenician script is an inscription on the sarcophagus of King Ahiram. This script is the parent script of all western alphabets. By the tenth century two other forms can be distinguished namely Canaanite and Aramaic. The Aramaic gave rise to Hebrew.[11] The South Arabian alphabet, a sister script to the Phoenician alphabet, is the script from which the Ge'ez alphabet (an abugida) is descended. Vowelless alphabets, which are not true alphabets, are called abjads, currently exemplified in scripts including Arabic, Hebrew, and Syriac. The omission of vowels was not a satisfactory solution and some "weak" consonants were used to indicate the vowel quality of a syllable (matres lectionis). These had dual function since they were also used as pure consonants.[12]
The Proto-Sinatic or Proto Canaanite script and the Ugaritic script were the first scripts with limited number of signs, in contrast to the other widely used writing systems at the time, Cuneiform, Egyptian hieroglyphs, and Linear B. The Phoenician script was probably the first phonemic script[8][10] and it contained only about two dozen distinct letters, making it a script simple enough for common traders to learn. Another advantage of Phoenician was that it could be used to write down many different languages, since it recorded words phonemically.
The script was spread by the Phoenicians, across the Mediterranean.[10] In Greece, the script was modified to add the vowels, giving rise to the ancestor of all alphabets in the West. The indication of the vowels is the same way as the indication of the consonants, therefore it was the first true alphabet. The Greeks took letters which did not represent sounds that existed in Greek, and changed them to represent the vowels. The vowels are significant in the Greek language, and the syllabical Linear B script which was used by the Mycenaean Greeks from the 16th century BC had 87 symbols including 5 vowels. In its early years, there were many variants of the Greek alphabet, a situation which caused many different alphabets to evolve from it.
European alphabets[edit]
Codex Zographensis in the Glagolitic alphabet from Medieval Bulgaria
The Greek alphabet, in its Euboean form, was carried over by Greek colonists to the Italian peninsula, where it gave rise to a variety of alphabets used to write the Italic languages. One of these became the Latin alphabet, which was spread across Europe as the Romans expanded their empire. Even after the fall of the Roman state, the alphabet survived in intellectual and religious works. It eventually became used for the descendant languages of Latin (the Romance languages) and then for most of the other languages of Europe.
Some adaptations of the Latin alphabet are augmented with ligatures, such as æ in Old English and Icelandic and ? in Algonquian; by borrowings from other alphabets, such as the thorn þ in Old English and Icelandic, which came from the Futhark runes; and by modifying existing letters, such as the eth ð of Old English and Icelandic, which is a modified d. Other alphabets only use a subset of the Latin alphabet, such as Hawaiian, and Italian, which uses the letters j, k, x, y and w only in foreign words.
Another notable script is Elder Futhark, which is believed to have evolved out of one of the Old Italic alphabets. Elder Futhark gave rise to a variety of alphabets known collectively as the Runic alphabets. The Runic alphabets were used for Germanic languages from AD 100 to the late Middle Ages. Its usage is mostly restricted to engravings on stone and jewelry, although inscriptions have also been found on bone and wood. These alphabets have since been replaced with the Latin alphabet, except for decorative usage for which the runes remained in use until the 20th century.
The Old Hungarian script is a contemporary writing system of the Hungarians. It was in use during the entire history of Hungary, albeit not as an official writing system. From the 19th century it once again became more and more popular.
The Glagolitic alphabet was the initial script of the liturgical language Old Church Slavonic and became, together with the Greek uncial script, the basis of the Cyrillic script. Cyrillic is one of the most widely used modern alphabetic scripts, and is notable for its use in Slavic languages and also for other languages within the former Soviet Union. Cyrillic alphabets include the Serbian, Macedonian, Bulgarian, and Russian alphabets. The Glagolitic alphabet is believed to have been created by Saints Cyril and Methodius, while the Cyrillic alphabet was invented by the Bulgarian scholar Clement of Ohrid, who was their disciple. They feature many letters that appear to have been borrowed from or influenced by the Greek alphabet and the Hebrew alphabet.
Asian alphabets[edit]
Beyond the logographic Chinese writing, many phonetic scripts are in existence in Asia. The Arabic alphabet, Hebrew alphabet, Syriac alphabet, and other abjads of the Middle East are developments of the Aramaic alphabet, but because these writing systems are largely consonant-based they are often not considered true alphabets.
Most alphabetic scripts of India and Eastern Asia are descended from the Brahmi script, which is often believed to be a descendant of Aramaic.
Zhuyin on a cell phone
In Korea, the Hangul alphabet was created by Sejong the Great[13] Hangul is a unique alphabet: it is a featural alphabet, where many of the letters are designed from a sound's place of articulation (P to look like the widened mouth, L to look like the tongue pulled in, etc.); its design was planned by the government of the day; and it places individual letters in syllable clusters with equal dimensions, in the same way as Chinese characters, to allow for mixed-script writing[citation needed] (one syllable always takes up one type-space no matter how many letters get stacked into building that one sound-block).
Zhuyin (sometimes called Bopomofo) is a semi-syllabary used to phonetically transcribe Mandarin Chinese in the Republic of China. After the later establishment of the People's Republic of China and its adoption of Hanyu Pinyin, the use of Zhuyin today is limited, but it's still widely used in Taiwan where the Republic of China still governs. Zhuyin developed out of a form of Chinese shorthand based on Chinese characters in the early 1900s and has elements of both an alphabet and a syllabary. Like an alphabet the phonemes of syllable initials are represented by individual symbols, but like a syllabary the phonemes of the syllable finals are not; rather, each possible final (excluding the medial glide) is represented by its own symbol. For example, luan is represented as ??? (l-u-an), where the last symbol ? represents the entire final -an. While Zhuyin is not used as a mainstream writing system, it is still often used in ways similar to a romanization system—that is, for aiding in pronunciation and as an input method for Chinese characters on computers and cellphones.
European alphabets, especially Latin and Cyrillic, have been adapted for many languages of Asia. Arabic is also widely used, sometimes as an abjad (as with Urdu and Persian) and sometimes as a complete alphabet (as with Kurdish and Uyghur).
Types[edit]
Alphabets: Armenian , Cyrillic , Georgian , Greek , Latin , Latin (and Arabic) , Latin and Cyrillic
Abjads: Arabic , Hebrew
Abugidas: North Indic , South Indic , Ge'ez , Tana , Canadian Syllabic and Latin
Logographic+syllabic: Pure logographic , Mixed logographic and syllabaries , Featural-alphabetic syllabary + limited logographic , Featural-alphabetic syllabary
History of the alphabet[show]
--------------------------------------------------------------------------------
The term "alphabet" is used by linguists and paleographers in both a wide and a narrow sense. In the wider sense, an alphabet is a script that is segmental at the phoneme level—that is, it has separate glyphs for individual sounds and not for larger units such as syllables or words. In the narrower sense, some scholars distinguish "true" alphabets from two other types of segmental script, abjads and abugidas. These three differ from each other in the way they treat vowels: abjads have letters for consonants and leave most vowels unexpressed; abugidas are also consonant-based, but indicate vowels with diacritics to or a systematic graphic modification of the consonants. In alphabets in the narrow sense, on the other hand, consonants and vowels are written as independent letters.[14] The earliest known alphabet in the wider sense is the Wadi el-Hol script, believed to be an abjad, which through its successor Phoenician is the ancestor of modern alphabets, including Arabic, Greek, Latin (via the Old Italic alphabet), Cyrillic (via the Greek alphabet) and Hebrew (via Aramaic).
Examples of present-day abjads are the Arabic and Hebrew scripts; true alphabets include Latin, Cyrillic, and Korean hangul; and abugidas are used to write Tigrinya, Amharic, Hindi, and Thai. The Canadian Aboriginal syllabics are also an abugida rather than a syllabary as their name would imply, since each glyph stands for a consonant which is modified by rotation to represent the following vowel. (In a true syllabary, each consonant-vowel combination would be represented by a separate glyph.)
All three types may be augmented with syllabic glyphs. Ugaritic, for example, is basically an abjad, but has syllabic letters for /?a, ?i, ?u/. (These are the only time vowels are indicated.) Cyrillic is basically a true alphabet, but has syllabic letters for /ja, je, ju/ (?, ?, ?); Coptic has a letter for /ti/. Devanagari is typically an abugida augmented with dedicated letters for initial vowels, though some traditions use ? as a zero consonant as the graphic base for such vowels.
The boundaries between the three types of segmental scripts are not always clear-cut. For example, Sorani Kurdish is written in the Arabic script, which is normally an abjad. However, in Kurdish, writing the vowels is mandatory, and full letters are used, so the script is a true alphabet. Other languages may use a Semitic abjad with mandatory vowel diacritics, effectively making them abugidas. On the other hand, the Phagspa script of the Mongol Empire was based closely on the Tibetan abugida, but all vowel marks were written after the preceding consonant rather than as diacritic marks. Although short a was not written, as in the Indic abugidas, one could argue that the linear arrangement made this a true alphabet. Conversely, the vowel marks of the Tigrinya abugida and the Amharic abugida (ironically, the original source of the term "abugida") have been so completely assimilated into their consonants that the modifications are no longer systematic and have to be learned as a syllabary rather than as a segmental script. Even more extreme, the Pahlavi abjad eventually became logographic. (See below.)
Ge'ez Script of Ethiopia
Thus the primary classification of alphabets reflects how they treat vowels. For tonal languages, further classification can be based on their treatment of tone, though names do not yet exist to distinguish the various types. Some alphabets disregard tone entirely, especially when it does not carry a heavy functional load, as in Somali and many other languages of Africa and the Americas. Such scripts are to tone what abjads are to vowels. Most commonly, tones are indicated with diacritics, the way vowels are treated in abugidas. This is the case for Vietnamese (a true alphabet) and Thai (an abugida). In Thai, tone is determined primarily by the choice of consonant, with diacritics for disambiguation. In the Pollard script, an abugida, vowels are indicated by diacritics, but the placement of the diacritic relative to the consonant is modified to indicate the tone. More rarely, a script may have separate letters for tones, as is the case for Hmong and Zhuang. For most of these scripts, regardless of whether letters or diacritics are used, the most common tone is not marked, just as the most common vowel is not marked in Indic abugidas; in Zhuyin not only is one of the tones unmarked, but there is a diacritic to indicate lack of tone, like the virama of Indic.
The number of letters in an alphabet can be quite small. The Book Pahlavi script, an abjad, had only twelve letters at one point, and may have had even fewer later on. Today the Rotokas alphabet has only twelve letters. (The Hawaiian alphabet is sometimes claimed to be as small, but it actually consists of 18 letters, including the ?okina and five long vowels.) While Rotokas has a small alphabet because it has few phonemes to represent (just eleven), Book Pahlavi was small because many letters had been conflated—that is, the graphic distinctions had been lost over time, and diacritics were not developed to compensate for this as they were in Arabic, another script that lost many of its distinct letter shapes. For example, a comma-shaped letter represented g, d, y, k, or j. However, such apparent simplifications can perversely make a script more complicated. In later Pahlavi papyri, up to half of the remaining graphic distinctions of these twelve letters were lost, and the script could no longer be read as a sequence of letters at all, but instead each word had to be learned as a whole—that is, they had become logograms as in Egyptian Demotic. The alphabet in the Polish language contains 32 letters.
The largest segmental script is probably an abugida, Devanagari. When written in Devanagari, Vedic Sanskrit has an alphabet of 53 letters, including the visarga mark for final aspiration and special letters for kš and jñ, though one of the letters is theoretical and not actually used. The Hindi alphabet must represent both Sanskrit and modern vocabulary, and so has been expanded to 58 with the khutma letters (letters with a dot added) to represent sounds from Persian and English.
The largest known abjad is Sindhi, with 51 letters. The largest alphabets in the narrow sense include Kabardian and Abkhaz (for Cyrillic), with 58 and 56 letters, respectively, and Slovak (for the Latin script), with 46. However, these scripts either count di- and tri-graphs as separate letters, as Spanish did with ch and ll until recently, or uses diacritics like Slovak c. The largest true alphabet where each letter is graphically independent is probably Georgian, with 41 letters.
Syllabaries typically contain 50 to 400 glyphs, and the glyphs of logographic systems typically number from the many hundreds into the thousands. Thus a simple count of the number of distinct symbols is an important clue to the nature of an unknown script.
Alphabetical order[edit]
Main article: Alphabetical order
Alphabets often come to be associated with a standard ordering of their letters, which can then be used for purposes of collation – namely for the listing of words and other items in what is called alphabetical order.
The basic ordering of the Latin alphabet (ABCDEFGHIJKLMNOPQRSTUVWXYZ), which is derived from the Northwest Semitic "Abgad" order,[15] is well established, although languages using this alphabet have different conventions for their treatment of modified letters (such as the French é, à, and ô) and of certain combinations of letters (multigraphs). In French, these are not considered to be additional letters for the purposes of collation. However, in Icelandic, the accented letters such as á, í, and ö are considered to be distinct letters of the alphabet. In Spanish, ñ is considered a separate letter, but accented vowels such as á and é are not. The ll and ch were also considered single letters, but in 1994 the Real Academia Española changed collating order so that ll is between lk and lm in the dictionary and ch is between cg and ci, and in 2010 the tenth congress of the Association of Spanish Language Academies changed it so they were no longer letters at all[16][17]
In German, words starting with sch- (constituting the German phoneme /?/) would be intercalated between words with initial sca- and sci- (all incidentally loanwords) instead of this graphic cluster appearing after the letter s, as though it were a single letter—a lexicographical policy which would be de rigueur in a dictionary of Albanian, i.e. dh-, ë-, gj-, ll-, rr-, th-, xh- and zh- (all representing phonemes and considered separate single letters) would follow the letters d, e, g, l, n, r, t, x and z respectively. Nor is, in a dictionary of English, the lexical section with initial th- reserved a place after the letter t, but is inserted between te- and ti-. German words with umlaut would further be alphabetized as if there were no umlaut at all—contrary to Turkish which allegedly adopted the German graphemes ö and ü, and where a word like tüfek, would come after tuz, in the dictionary. An exception is the German phonebook where umlauts are sorted like ä = ae since names as Jäger appear also with the spelling Jaeger, and there's no telling them apart in the spoken language.
The Danish and Norwegian alphabets end with æ—ø—å, whereas the Icelandic, Swedish, Finnish and Estonian ones conventionally put å—ä—ö at the end.
It is unknown whether the earliest alphabets had a defined sequence. Some alphabets today, such as the Hanuno'o script, are learned one letter at a time, in no particular order, and are not used for collation where a definite order is required. However, a dozen Ugaritic tablets from the fourteenth century BC preserve the alphabet in two sequences. One, the ABCDE order later used in Phoenician, has continued with minor changes in Hebrew, Greek, Armenian, Gothic, Cyrillic, and Latin; the other, HMHLQ, was used in southern Arabia and is preserved today in Ethiopic.[18] Both orders have therefore been stable for at least 3000 years.
The historical order was abandoned in Runic and Arabic, although Arabic retains the traditional abjadi order for numbering.
The Brahmic family of alphabets used in India use a unique order based on phonology: The letters are arranged according to how and where they are produced in the mouth. This organization is used in Southeast Asia, Tibet, Korean hangul, and even Japanese kana, which is not an alphabet.
Names of letters[edit]
The Phoenician letter names, in which each letter was associated with a word that begins with that sound, continue to be used to varying degrees in Samaritan, Aramaic, Syriac, Hebrew, Greek and Arabic. The names were abandoned in Latin, which instead referred to the letters by adding a vowel (usually e) before or after the consonant (the exception is zeta, which was retained from Greek). In Cyrillic originally the letters were given names based on Slavic words; this was later abandoned as well in favor of a system similar to that used in Latin.
Orthography and pronunciation[edit]
Main article: Phonemic orthography
When an alphabet is adopted or developed for use in representing a given language, an orthography generally comes into being, providing rules for the spelling of words in that language. In accordance with the principle on which alphabets are based, these rules will generally map letters of the alphabet to the phonemes (significant sounds) of the spoken language. In a perfectly phonemic orthography there would be a consistent one-to-one correspondence between the letters and the phonemes, so that a writer could predict the spelling of a word given its pronunciation, and a speaker could predict the pronunciation of a word given its spelling. However this ideal is not normally achieved in practice; some languages (such as Spanish and Finnish) come close to it, while others (such as English) deviate from it to a much larger degree.
The pronunciation of a language often evolves independently of its writing system, and writing systems have been borrowed for languages they were not designed for, so the degree to which letters of an alphabet correspond to phonemes of a language varies greatly from one language to another and even within a single language.
Languages may fail to achieve a one-to-one correspondence between letters and sounds in any of several ways:
A language may represent a given phoneme with a combination of letters rather than just a single letter. Two-letter combinations are called digraphs and three-letter groups are called trigraphs. German uses the tesseragraphs (four letters) "tsch" for the phoneme [t?] and "dsch" for [d?], although the latter is rare. Kabardian also uses a tesseragraph for one of its phonemes, namely "????". Two letters representing one sound is widely used in Hungarian as well (where, for instance, cs stands for [c], sz for [s], zs for [ž], dzs for [j], etc.).
A language may represent the same phoneme with two different letters or combinations of letters. An example is modern Greek which may write the phoneme [i] in six different ways: ???, ???, ???, ?e??, ????, and ???? (although the last is rare).
A language may spell some words with unpronounced letters that exist for historical or other reasons. For example, the spelling of the Thai word for "beer" [??????] retains a letter for the final consonant "r" present in the English word it was borrowed from, but silences it.
Pronunciation of individual words may change according to the presence of surrounding words in a sentence (sandhi).
Different dialects of a language may use different phonemes for the same word.
A language may use different sets of symbols or different rules for distinct sets of vocabulary items, such as the Japanese hiragana and katakana syllabaries, or the various rules in English for spelling words from Latin and Greek, or the original Germanic vocabulary.
National languages generally elect to address the problem of dialects by simply associating the alphabet with the national standard. However, with an international language with wide variations in its dialects, such as English, it would be impossible to represent the language in all its variations with a single phonetic alphabet.
Some national languages like Finnish, Turkish, Serbo-Croatian (Serbian, Croatian and Bosnian) and Bulgarian have a very regular spelling system with a nearly one-to-one correspondence between letters and phonemes. Strictly speaking, these national languages lack a word corresponding to the verb "to spell" (meaning to split a word into its letters), the closest match being a verb meaning to split a word into its syllables. Similarly, the Italian verb corresponding to 'spell (out)', compitare, is unknown to many Italians because the act of spelling itself is rarely needed: Italian spelling is highly phonemic. In standard Spanish, it is possible to tell the pronunciation of a word from its spelling, but not vice versa; this is because certain phonemes can be represented in more than one way, but a given letter is consistently pronounced. French, with its silent letters and its heavy use of nasal vowels and elision, may seem to lack much correspondence between spelling and pronunciation, but its rules on pronunciation, though complex, are actually consistent and predictable with a fair degree of accuracy.
At the other extreme are languages such as English, where the spelling of many words simply has to be memorized as they do not correspond to sounds in a consistent way. For English, this is partly because the Great Vowel Shift occurred after the orthography was established, and because English has acquired a large number of loanwords at different times, retaining their original spelling at varying levels. Even English has general, albeit complex, rules that predict pronunciation from spelling, and these rules are successful most of the time; rules to predict spelling from the pronunciation have a higher failure rate.
Sometimes, countries have the written language undergo a spelling reform to realign the writing with the contemporary spoken language. These can range from simple spelling changes and word forms to switching the entire writing system itself, as when Turkey switched from the Arabic alphabet to a Turkish alphabet of Latin origin.
The sounds of speech of all languages of the world can be written by a rather-small universal phonetic-alphabet. A standard for this is the International Phonetic Alphabet.
See also[edit]
A Is For Aardvark
Abecedarium
Acrophony
Akshara
Alphabet Effect
Alphabet song
Alphabetical order
Alphabetize
Butterfly Alphabet
Character encoding
Constructed script
Cyrillic
English alphabet
Hangul
ICAO spelling alphabet
Lipogram
List of alphabets
Pangram
Thai script
Transliteration
Unicode
References[edit]
1.^ Coulmas, Florian (1996). The Blackwell Encyclopedia of Writing Systems. Oxford: Blackwell Publishing. ISBN 0-631-21481-X.
2.^ Millard 1986, p. 396
3.^ Haarmann 2004, p. 96
4.^ Encyclopædia Britannica Online – Merriam-Webster's Online Dictionary
5.^ "The Development of the Western Alphabet". h2g2. BBC. 2004-04-08. Retrieved 2008-08-04.
6.^ Daniels and Bright (1996), pp. 74–75
7.^ J. C. Darnell, F. W. Dobbs-Allsopp, Marilyn J. Lundberg, P. Kyle McCarter, and Bruce Zuckermanet, “Two early alphabetic inscriptions from the Wadi el-Hol: new evidence for the origin of the alphabet from the western desert of Egypt.” The Annual of the American Schools of Oriental Research, 59 (2005).
8.^ a b Coulmas (1989), p. 140–141.
9.^ Ugaritic Writing online
10.^ a b c Daniels and Bright (1996), pp 92-96
11.^ "Coulmas"(1989),p.142
12.^ "Coulmas" (1989) p.147.
13.^ "?????????…??????(His majesty created 28 characters himself... It is Hunminjeongeum (original name for Hangul))", «???? (The Annals of the Choson Dynasty : Sejong)» 25? 12?.
14.^ For critics of the abjad-abugida-alphabet distinction, see Reinhard G. Lehmann: "27-30-22-26. How Many Letters Needs an Alphabet? The Case of Semitic", in: The idea of writing: Writing across borders / edited by Alex de Voogt and Joachim Friedrich Quack, Leiden: Brill 2012, p. 11-52, esp p. 22-27
15.^ Reinhard G. Lehmann: "27-30-22-26. How Many Letters Needs an Alphabet? The Case of Semitic", in: The idea of writing: Writing across borders / edited by Alex de Voogt and Joachim Friedrich Quack, Leiden: Brill 2012, p. 11-52
16.^ Real Academia Española. "Spanish Pronto!: Spanish Alphabet." Spanish Pronto! 22 April 2007. January 2009 Spanish Pronto: Spanish < > English Medical Translators.
17.^ "La “i griega” se llamará “ye”". Cuba Debate. 2010-11-05. Retrieved 12 December 2010. Cubadebate.cu
18.^ Millard, A.R. "The Infancy of the Alphabet", World Archaeology 17, No. 3, Early Writing Systems (February 1986): 390–398. page 395.
Bibliography[edit]
Coulmas, Florian (1989). The Writing Systems of the World. Blackwell Publishers Ltd. ISBN 0-631-18028-1.
Daniels, Peter T.; Bright, William (1996). The World's Writing Systems. Oxford University Press. ISBN 0-19-507993-0. Overview of modern and some ancient writing systems.
Driver, G. R. (1976). Semitic Writing (Schweich Lectures on Biblical Archaeology S.) 3Rev Ed. Oxford University Press. ISBN 0-19-725917-0.
Haarmann, Harald (2004). Geschichte der Schrift (2nd ed.). München: C. H. Beck. ISBN 3-406-47998-7
Hoffman, Joel M. (2004). In the Beginning: A Short History of the Hebrew Language. NYU Press. ISBN 0-8147-3654-8. Chapter 3 traces and summarizes the invention of alphabetic writing.
Logan, Robert K. (2004). The Alphabet Effect: A Media Ecology Understanding of the Making of Western Civilization. Hampton Press. ISBN 1-57273-523-6.
McLuhan, Marshall; Logan, Robert K. (1977). Alphabet, Mother of Invention. Etcetera. Vol. 34, pp. 373–383
Millard, A. R. (1986). "The Infancy of the Alphabet". World Archaeology 17 (3): 390–398. doi:10.1080/00438243.1986.9979978
Ouaknin, Marc-Alain; Bacon, Josephine (1999). Mysteries of the Alphabet: The Origins of Writing. Abbeville Press. ISBN 0-7892-0521-1.
Powell, Barry (1991). Homer and the Origin of the Greek Alphabet. Cambridge University Press. ISBN 0-521-58907-X.
Powell, Barry B. 2009. Writing: Theory and History of the Technology of Civilization, Oxford: Blackwell. ISBN 978-1-4051-6256-2
Sacks, David (2004). Letter Perfect: The Marvelous History of Our Alphabet from A to Z (PDF). Broadway Books. ISBN 0-7679-1173-3.
Saggs, H. W. F. (1991). Civilization Before Greece and Rome. Yale University Press. ISBN 0-300-05031-3. Chapter 4 traces the invention of writing
External links[edit]
Look up alphabet in Wiktionary, the free dictionary.
The Origins of abc
"Language, Writing and Alphabet: An Interview with Christophe Rico", Damqatum 3 (2007)
Alphabetic Writing Systems
Michael Everson's Alphabets of Europe
Evolution of alphabets, animation by Prof. Robert Fradkin at the University of Maryland
How the Alphabet Was Born from Hieroglyphs—Biblical Archaeology Review
English alphabet - Wikipedia, the free encyclopedia
en.wikipedia.org/wiki/English_alphabet?
The modern English alphabet is a Latin alphabet consisting of 26 letters – the same letters that are found in the ISO basic Latin alphabet:...
English alphabet
From Wikipedia, the free encyclopedia
"The Alphabet" redirects here. For the short film by David Lynch, see The Alphabet (film).
The modern English alphabet is a Latin alphabet consisting of 26 letters – the same letters that are found in the ISO basic Latin alphabet:
Majuscule forms (also called uppercase or capital letters)
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
Minuscule forms (also called lowercase or small letters)
a b c d e f g h i j k l m n o p q r s t u v w x y z
The exact shape of printed letters varies depending on the typeface. The shape of handwritten letters can differ significantly from the standard printed form (and between individuals), especially when written in cursive style. See the individual letter articles for information about letter shapes and origins (follow the links on any of the uppercase letters above).
Written English uses a number of digraphs, such as ch, sh, th, wh, qu, etc., but they are not considered separate letters of the alphabet. Some traditions also use two ligatures, æ and œ,[1] or consider the ampersand (&) part of the alphabet.
English alphabet
Contents
[hide] 1 History 1.1 Old English
1.2 Modern English
2 Diacritics
3 Ampersand
4 Apostrophe
5 Letter names 5.1 Etymology
6 Phonology
7 Letter frequencies
8 See also
9 Footnotes
History[edit]
See also: History of the Latin alphabet and English orthography
Old English[edit]
Main article: Old English Latin alphabet
The English language was first written in the Anglo-Saxon futhorc runic alphabet, in use from the 5th century. This alphabet was brought to what is now England, along with the proto-form of the language itself, by Anglo-Saxon settlers. Very few examples of this form of written Old English have survived, these being mostly short inscriptions or fragments.
The Latin script, introduced by Christian missionaries, began to replace the Anglo-Saxon futhorc from about the 7th century, although the two continued in parallel for some time. Futhorc influenced the emerging English alphabet by providing it with the letters thorn (Þ þ) and wynn (? ?). The letter eth (Ð ð) was later devised as a modification of dee (D d), and finally yogh (? ?) was created by Norman scribes from the insular g in Old English and Irish, and used alongside their Carolingian g.
The a-e ligature ash (Æ æ) was adopted as a letter its own right, named after a futhorc rune æsc. In very early Old English the o-e ligature ethel (Œ œ) also appeared as a distinct letter, likewise named after a rune, œðel. Additionally, the v-v or u-u ligature double-u (W w) was in use.
In the year 1011, a writer named Byrhtferð ordered the Old English alphabet for numerological purposes.[2] He listed the 24 letters of the Latin alphabet (including ampersand) first, then 5 additional English letters, starting with the Tironian note ond (?) an insular symbol for and:
A B C D E F G H I K L M N O P Q R S T V X Y Z & ? ? Þ Ð Æ
Modern English[edit]
In the orthography of Modern English, thorn (þ), eth (ð), wynn (?), yogh (?), ash (æ), and ethel (œ) are obsolete. Latin borrowings reintroduced homographs of ash and ethel into Middle English and Early Modern English, though they are not considered to be the same letters[citation needed] but rather ligatures, and in any case are somewhat old-fashioned. Thorn and eth were both replaced by th,[citation needed] though thorn continued in existence for some time, its lowercase form gradually becoming graphically indistinguishable from the minuscule y in most handwriting. Y for th can still be seen in pseudo-archaisms such as "Ye Olde Booke Shoppe". The letters þ and ð are still used in present-day Icelandic and Faroese. Wynn disappeared from English around the fourteenth century when it was supplanted by uu, which ultimately developed into the modern w. Yogh disappeared around the fifteenth century and was typically replaced by gh.
The letters u and j, as distinct from v and i, were introduced in the 16th century, and w assumed the status of an independent letter, so that the English alphabet is now considered to consist of the following 26 letters:
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
The variant lowercase form long s (?) lasted into early modern English, and was used in non-final position up to the early 19th century.
The ligatures æ and œ are still used in formal writing for certain words of Greek or Latin origin, such as encyclopædia and cœlom. Lack of awareness and technological limitations (such as their absence from the standard qwerty keyboard) have made it common to see these rendered as "ae" and "oe", respectively, in modern, non-academic usage. These ligatures are not used in American English, where a lone e has mostly supplanted both (for example, encyclopedia for encyclopædia, and fetus for fœtus).
Diacritics[edit]
Main article: English terms with diacritical marks
Question book-new.svg
This section does not cite any references or sources. Please help improve this section by adding citations to reliable sources. Unsourced material may be challenged and removed. (June 2011)
Diacritic marks mainly appear in loanwords such as naïve and façade. As such words become naturalised In English, there is a tendency to drop the diacritics, as has happened with old borrowings such as hôtel, from French. Informal English writing tends to omit diacritics because of their absence from the computer keyboard, while professional copywriters and typesetters tend to include them. Words that are still perceived as foreign tend to retain them; for example, the only spelling of soupçon found in English dictionaries (the OED and others) uses the diacritic. Diacritics are also more likely to be retained where there would otherwise be confusion with another word (for example, résumé rather than resume), and, rarely, even added (as in maté, from Spanish yerba mate, but following the pattern of café, from French).
Occasionally, especially in older writing, diacritics are used to indicate the syllables of a word: cursed (verb) is pronounced with one syllable, while cursèd (adjective) is pronounced with two. È is used widely in poetry, e.g. in Shakespeare's sonnets. Similarly, while in chicken coop the letters -oo- represent a single vowel sound (a digraph), in zoölogist and coöperation, they represent two. An acute, grave or diaeresis may also be placed over an 'e' at the end of a word to indicate that it is not silent, as in saké. However, in practice these devices are often not used even where they would serve to alleviate some degree of confusion.
Ampersand[edit]
The & has sometimes appeared at the end of the English alphabet, as in Byrhtferð's list of letters in 1011.[2] Historically, the figure is a ligature for the letters Et. In English it is used to represent the word and and occasionally the Latin word et, as in the abbreviation &c (et cetera).
Apostrophe[edit]
Question book-new.svg
This section does not cite any references or sources. Please help improve this section by adding citations to reliable sources. Unsourced material may be challenged and removed. (June 2011)
The apostrophe, while not considered part of the English alphabet, is used to abbreviate English words. A few pairs of words, such as its (belonging to it) and it's (it is or it has), were (plural of was) and we're (we are), and shed (to get rid of) and she'd (she would or she had) are distinguished in writing only by the presence or absence of an apostrophe. The apostrophe also distinguishes the possessive endings -'s and -s' from the common plural ending -s, a practice introduced in the 18th century; before, all three endings were written -s, which could lead to confusion (as in, the Apostles words).
Letter names[edit]
The names of the letters are rarely spelled out, except when used in derivations or compound words (for example tee-shirt, deejay, emcee, okay, aitchless, wye-level, etc.), derived forms (for example exed out, effing, to eff and blind, etc.), and in the names of objects named after letters (for example em (space) in printing and wye (junction) in railroading). The forms listed below are from the Oxford English Dictionary. Vowels stand for themselves, and consonants usually have the form consonant + ee or e + consonant (e.g. bee and ef). The exceptions are the letters aitch, jay, kay, cue, ar, ess (but es- in compounds ), wye, and zed. Plurals of consonants end in -s (bees, efs, ems) or, in the cases of aitch, ess, and ex, in -es (aitches, esses, exes). Plurals of vowels end in -es (aes, ees, ies, oes, ues); these are rare. Of course, all letters may stand for themselves, generally in capitalized form (okay or OK, emcee or MC), and plurals may be based on these (aes or A's, cees or C's, etc.)
Letter
Letter name
Pronunciation
A a /e?/[3]
B bee /bi?/
C cee /si?/
D dee /di?/
E e /i?/
F ef (eff as a verb) /?f/
G gee /d?i?/
H aitch /e?t?/
haitch[4] /he?t?/
I i /a?/
J jay /d?e?/
jy[5] /d?a?/
K kay /ke?/
L el or ell /?l/
M em /?m/
N en /?n/
O o /o?/
P pee /pi?/
Q cue /kju?/
R ar /?r/[6]
S ess (es-)[7] /?s/
T tee /ti?/
U u /ju?/
V vee /vi?/
W double-u /'d?b?l.ju?/[8]
X ex /?ks/
Y wy or wye /wa?/
Z zed[9] /z?d/
zee[10] /zi?/
izzard[11] /'?z?rd/
Some groups of letters, such as pee and bee, or em and en, are easily confused in speech, especially when heard over the telephone or a radio communications link. Spelling alphabets such as the ICAO spelling alphabet, used by aircraft pilots, police and others, are designed to eliminate this potential confusion by giving each letter a name that sounds quite different from any other.
Etymology[edit]
The names of the letters are for the most part direct descendents, via French, of the Latin (and Etruscan) names. (See Latin alphabet: Origins.)
Letter
Latin
Old French
Middle English
Modern English
A á /a?/ /a?/ /a?/ /e?/
B bé /be?/ /be?/ /be?/ /bi?/
C cé /ke?/ /t?e?/ ? /tse?/ ? /se?/ /se?/ /si?/
D dé /de?/ /de?/ /de?/ /di?/
E é /e?/ /e?/ /e?/ /i?/
F ef /?f/ /?f/ /?f/ /?f/
G gé /ge?/ /d?e?/ /d?e?/ /d?i?/
H há /ha?/ ? /aha/ ? /ak?a/ /a?t?/ /a?t?/ /e?t?/
I í /i?/ /i?/ /i?/ /a?/
J – – – /d?e?/
K ká /ka?/ /ka?/ /ka?/ /ke?/
L el /?l/ /?l/ /?l/ /?l/
M em /?m/ /?m/ /?m/ /?m/
N en /?n/ /?n/ /?n/ /?n/
O ó /o?/ /o?/ /o?/ /o?/
P pé /pe?/ /pe?/ /pe?/ /pi?/
Q qú /ku?/ /ky?/ /kiw/ /kju?/
R er /?r/ /?r/ / ?r/ ? /ar/ /?r/
S es /?s/ /?s/ /?s/ /?s/
T té /te?/ /te?/ /te?/ /ti?/
U ú /u?/ /y?/ /iw/ /ju?/
V – – – /vi?/
W – – – /'d?b?l.ju?/
X ex /?ks, iks/ /iks/ /?ks/ /?ks/
Y hý /hy?, i?/
í graeca /'gra?ka/ ui, gui ?
i grec /i? gr??k/ /wi?/ ? /wa?/
Z zéta /ze?ta/ zed /z??d/
et zed /et ze?d/ ? /e zed/ /z?d/
/?'z?d/ /z?d, zi?/
/'?z?d/
The regular phonological developments (in rough chronological order) are:
palatalization before front vowels of Latin /k/ successively to /t?/, /ts/, and finally to Middle French /s/. Affects C.
palatalization before front vowels of Latin /g/ to Proto-Romance and Middle French /d?/. Affects G.
fronting of Latin /u?/ to Middle French /y?/, becoming Middle English /iw/ and then Modern English /ju?/. Affects Q, U.
the inconsistent lowering of Middle English /?r/ to /ar/. Affects R.
the Great Vowel Shift, shifting all Middle English long vowels. Affects A, B, C, D, E, G, H, I, K, O, P, T, and presumably Y.
The novel forms are aitch, a regular development of Medieval Latin acca; jay, a new letter presumably vocalized like neighboring kay to avoid confusion with established gee (the other name, jy, was taken from French); vee, a new letter named by analogy with the majority; double-u, a new letter, self-explanatory (the name of Latin V was u); wye, of obscure origin but with an antecedent in Old French wi; zee, an American leveling of zed by analogy with the majority; and izzard, from the Romance phrase i zed or i zeto "and Z" said when reciting the alphabet.
Phonology[edit]
Main article: English phonology
The letters A, E, I, O, and U are considered vowel letters, since (except when silent) they represent vowels; the remaining letters are considered consonant letters, since when not silent they generally represent consonants. However, Y commonly represents vowels as well as a consonant (e.g., "myth"), as very rarely does W (e.g., "cwm"). Conversely, U sometimes represents a consonant (e.g., "quiz").
Letter frequencies[edit]
Main article: Letter frequency
The letter most frequently used in English is E. The least frequently used letter is Z.
The list below shows the frequency of letter use in English.[12]
Letter
Frequency
A 8.17%
B 1.49%
C 2.78%
D 4.25%
E 12.70%
F 2.23%
G 2.02%
H 6.09%
I 6.97%
J 0.15%
K 0.77%
L 4.03%
M 2.41%
N 6.75%
O 7.51%
P 1.93%
Q 0.10%
R 5.99%
S 6.33%
T 9.06%
U 2.76%
V 0.98%
W 2.36%
X 0.15%
Y 1.97%
Z 0.07%
See also[edit]
English orthography
English spelling reform
American manual alphabet
Two-handed manual alphabets
English braille
American braille
New York Point
Footnotes[edit]
1.^ See also the section on Ligatures
2.^ a b Michael Everson, Evertype, Baldur Sigurðsson, Íslensk Málstöð, On the Status of the Latin Letter Þorn and of its Sorting Order
3.^ Sometimes /æ/ in Hiberno-English
4.^ sometimes in Australian and Irish English, and usually in Indian English (although often considered incorrect)
5.^ in Scottish English
6.^ /?r/ (/??r/?) in Hiberno-English[citation needed]
7.^ in compounds such as es-hook
8.^ Especially in American English, the /l/ is not often pronounced in informal speech. (Merriam Webster's Collegiate Dictionary, 10th ed). Common colloquial pronunciations are /'d?b?ju?/, /'d?b?j?/, and /'d?bj?/, as in the nickname "Dubya", especially in terms like www.
9.^ in British and Commonwealth English
10.^ in American English
11.^ in Scottish English
12.^ Beker, Henry; Piper, Fred (1982). Cipher Systems: The Protection of Communications. Wiley-Interscience. p. 397. Table also available from Lewand, Robert (2000). Cryptological Mathematics. The Mathematical Association of America. p. 36. ISBN 978-0883857199. and [1]
Description of the English language
Grammar·
Phonology·
Stress and reduced vowels·
Orthography·
Alphabet·
Dialects·
Language history·
Phonological history
Categories: English spelling
Latin alphabets
Languages
???????
?????????
Cesky
Deutsch
Eesti
Español
?????
Français
Gaelg
???
??????
Magyar
??????????
Polski
Português
Româna
???????
?????
??????
Türkçe
??????????
??
Edit links
This page was last modified on 5 June 2013 at 05:21.
1234 5 6789
Letter frequency - Wikipedia, the free encyclopedia
"The most common letter in the English alphabet is E."
Daily Mail, Wednesday, December 10, 2014
ANSWERS TO CORRESPONDENTS
Compiled by Charles Legge
QUESTION A Iipogram Is a constrained form of writing where a specific letter (often a vowel) is avoided altogether. Have any novels been written this way?
THE lipogram (Greek for 'leaving out a letter') is an ancient literary form, dating back to the 6th-century BC writer Lasus of Hermione, who wrote two composition for the voice in which he suppressed the sigma, one of the most common letters in Greek.
The first person to tackle it in novel form was U.S. author Ernest Vincent Wright, Gadsby, published in 1939, has 50,000 words and is completely without the letter E. The hero of the novel is a man named John Gadsby. The author went so far as to make the E on his typewriter inoperable, to avoid an E slipping into the text inadvertently.
Naturally he had to avoid the word pronouns such as 'he', 'she', 'her', 'them' `they', and past tenses that end in '-ed'. The numbers from seven to 30 had to be omitted as, to keep the text 'pure' the author would not substitute the numerical values — quite an achievement. It took about nine years to complete then some time to find a publisher.
A poetic lipogram, probably unintentional, is the six-line nursery rhyme Old Mother Hubbard which, surprisingly, does not contain the letter i.
Going further, there is one three-stanza poem, called Fate Of Nassan, in which each four-line stanza contains every letter of the alphabet except 'e'. The poem is anonymous but was composed before 1870.
C. D. Allan, Alsager, Stoke-on-Trent, Staffs.
PERHAPS the most-famous example is the Polish-Jewish-French writer Georges Perec, who died in 1982.
His 1969 novel, La Disparition, translated. into English (1994) by Gilbert Adair as A Void, was written without a single letter `e'. Ironic, really, since his own name contains no fewer than four example of that letter.
Frederick Robinson, Bexhill-on-Sea, East Sussex
Old Mother Hubbard - Wikipedia, the free encyclopedia
en.wikipedia.org/wiki/Old_Mother_Hubbard
Old Mother Hubbard Went to the cupboard, To give the poor dog a bone; When she came there, The cupboard was bare, And so the poor dog had none.
Letter frequency - Wikipedia, the free encyclopedia
"The most common letter in the English alphabet is E."
LOOK AT THE 5FIVES LOOK AT THE 5FIVES LOOK AT THE 5FIVES THE 5FIVES THE 5FIVES
LOOK AT THE 5 LOOK AT THE 5 LOOK AT THE 5 THE 5 THE 5
Daily Mail
Thursday, June 11 2009
Page 37
Web 2.0 - the one millionth English word
ALMOST 1,500 years after it was first recorded, the English language has its one millionth word.
At 10.22am yesterday Web 2.0 - describing the next generation of internet services entered the dictionary.
To be accepted a word must be used at least 25,000 times across national boundaries and outside specialisms.
U.S-based Global Language Monitor surveys print publications, online news sites, blogs and social media for useage.
Jai Ho!, a Hindi phrase signifying the joy of victory became the 999,999th word thanks to the Oscar-Winning film Slumdog millionaire.
At 1,000,001 is Financial Tsunami - a sudden financial restructuring.
"JAI HO! A HINDI PHRASE SIGNIFYING THE JOY OF VICTORY BECAME THE 999,999TH WORD..."
THE JESUS MYSTERIES
Timothy Freke & Peter Gandy
1
999
Page 177
The gospels are actually anonymous works, in which everything, without exception, is written in capital letters, with no headings, chapter or verse divisions, and practically no punctuation or spaces between words.61 They were not even written in the Aramic of the Jews but in Greek.62
THE GOSPELS ARE ACTUALLY ANONYMOUS WORKS,
IN WHICH EVERYTHING WITHOUT EXCEPTION, IS WRITTEN IN CAPITAL LETTERS,
WITH NO PUNCTUATION OR SPACES BETWEEN WORDS.
Essenes - Wikipedia, the free encyclopedia
https://en.wikipedia.org/wiki/Essenes
The Essenes (in Modern but not in Ancient Hebrew: אִסִּיִים, Isiyim; Greek: Εσσήνοι, Εσσαίοι, or Οσσαίοι, Essḗnoi, Essaíoi, Ossaíoi) were a sect of Second ...
Essenes
From Wikipedia, the free encyclopedia
Essene" redirects here. For the bread, see sprouted bread.
Part of a series on Jews and Judaism
Star of David
Etymology·
Who is a Jew?
Jewish peoplehood
Jewish identity
Religion[show]
The Essenes (in Modern but not in Ancient Hebrew: אִסִּיִים, Isiyim; Greek: Εσσήνοι, Εσσαίοι, or Οσσαίοι, Essḗnoi, Essaíoi, Ossaíoi) were a sect of Second Temple Judaism that flourished from the 2nd century BCE to the 1st century CE which some scholars claim seceded from the Zadokite priests.[1] Being much fewer in number than the Pharisees and the Sadducees (the other two major sects at the time), the Essenes lived in various cities but congregated in communal life dedicated to asceticism, voluntary poverty, daily immersion, and abstinence from worldly pleasures, including (for some groups) celibacy. Many separate but related religious groups of that era shared similar mystic, eschatological, messianic, and ascetic beliefs. These groups are collectively referred to by various scholars as the "Essenes." Josephus records that Essenes existed in large numbers, and thousands lived throughout Roman Judæa.
The Essenes have gained fame in modern times as a result of the discovery of an extensive group of religious documents known as the Dead Sea Scrolls, which are commonly believed to be Essenes' library—although there is no proof that the Essenes wrote them. These documents include preserved multiple copies of the Hebrew Bible untouched from as early as 300 BCE until their discovery in 1946. Some scholars, however, dispute the notion that the Essenes wrote the Dead Sea Scrolls.[2] Rachel Elior questions even the existence of the Essenes.[3][4][5]
The first reference is by the Roman writer Pliny the Elder (died c. 79 CE) in his Natural History.[6] Pliny relates in a few lines that the Essenes do not marry, possess no money, and had existed for thousands of generations. Unlike Philo, who did not mention any particular geographical location of the Essenes other than the whole land of Israel, Pliny places them in Ein Gedi, next to the Dead Sea.
A little later Josephus gave a detailed account of the Essenes in The Jewish War (c. 75 CE), with a shorter description in Antiquities of the Jews (c. 94 CE) and The Life of Flavius Josephus (c. 97 CE). Claiming first hand knowledge, he lists the Essenoi as one of the three sects of Jewish philosophy[7] alongside the Pharisees and the Sadducees. He relates the same information concerning piety, celibacy, the absence of personal property and of money, the belief in communality and commitment to a strict observance of Sabbath. He further adds that the Essenes ritually immersed in water every morning, ate together after prayer, devoted themselves to charity and benevolence, forbade the expression of anger, studied the books of the elders, preserved secrets, and were very mindful of the names of the angels kept in their sacred writings.
CATHOLIC ENCYCLOPEDIA: Essenes - New Advent
www.newadvent.org › Catholic Encyclopedia › E
One of three leading Jewish sects mentioned by Josephus as flourishing in the second century B.C., the others being the Pharisees and the Sadducees.
ESSENES
